大纲
一、mail 协议
二、mail 组件
三、mail 工作原理(两种对比)
四、安装前的准备工作
五、安装并配置LAMP环境
六、安装并配置postfixadmin
七、安装并配置phpmyadmin
八、配置postfix邮件发送代理
九、安装并配置dovecot邮件检索代理
十、测试SMTP与POP3服务
十一、安装并配置WebMail(Roundcubemail)
十二、安装并配置病毒扫描与垃圾邮件过滤
十三、安装并配置managesieve插件
十四、常见问题分析
注:系统,CentOS 6.4 X86_64 。软件,全部都是RPM包,有兴趣的博友可以尝试一下全部源码包安装!(所安装的主要软件如下,LAMP+Postfix+Dovecot+PostfixAdmin+Roundcubemail+Amavisd-new+ClamAV+SpamAssassin+Managesieve)
一、mail 协议
mail使用的协议有,
| 协议名称 |
协议类型 |
端口号 |
| smtp |
tcp |
25 |
| pop3 |
tcp |
110 |
| smtps |
tcp |
465 |
| pop3s |
tcp |
995 |
| imap |
tcp |
143 |
| imaps |
tcp |
993 |
二、mail 组件
1.MTA:mail transfer agent 邮件传输代理
常见软件,
Exchange(微软)
Sendmail 开源的软件 目前有50%的邮件服务器使用这个软件
Postfix 现在用的挺多
Qmail 昙花一现
Exim(英国剑桥大学开发的)
2.MRA:mail retravial agent 邮件检索代理
常见软件,
courier-imap:pop3,imap4,imaps,pop3s (俄罗斯开发)
dovecot (主流)
3.MDA:mail delivery agent 邮件投递代理
常见软件,
procmail (postfix默认)
maildrop (功能强大,效率高)
4.MUA:mail user agent 邮件用户代理
常见软件,
outlook express
Foxmail
pine(linux)
mutt(linux,经常用到的)
5.Mailbox 信箱
mailbox
maildir (主流)
两者的主要区别,mailbox是把所有邮件放在同一个文件中,maildir把每个用户的邮件都单独存放
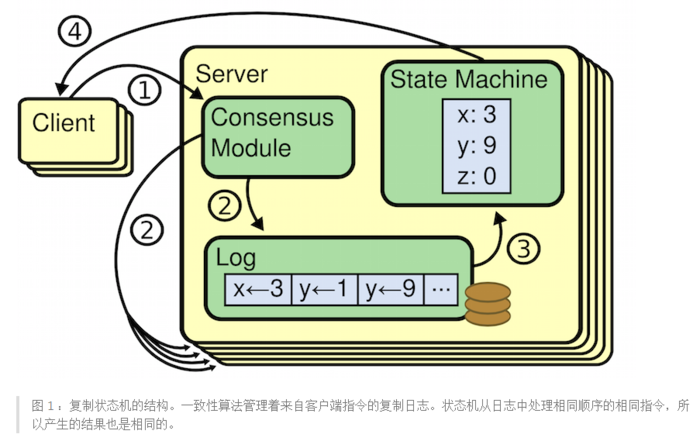
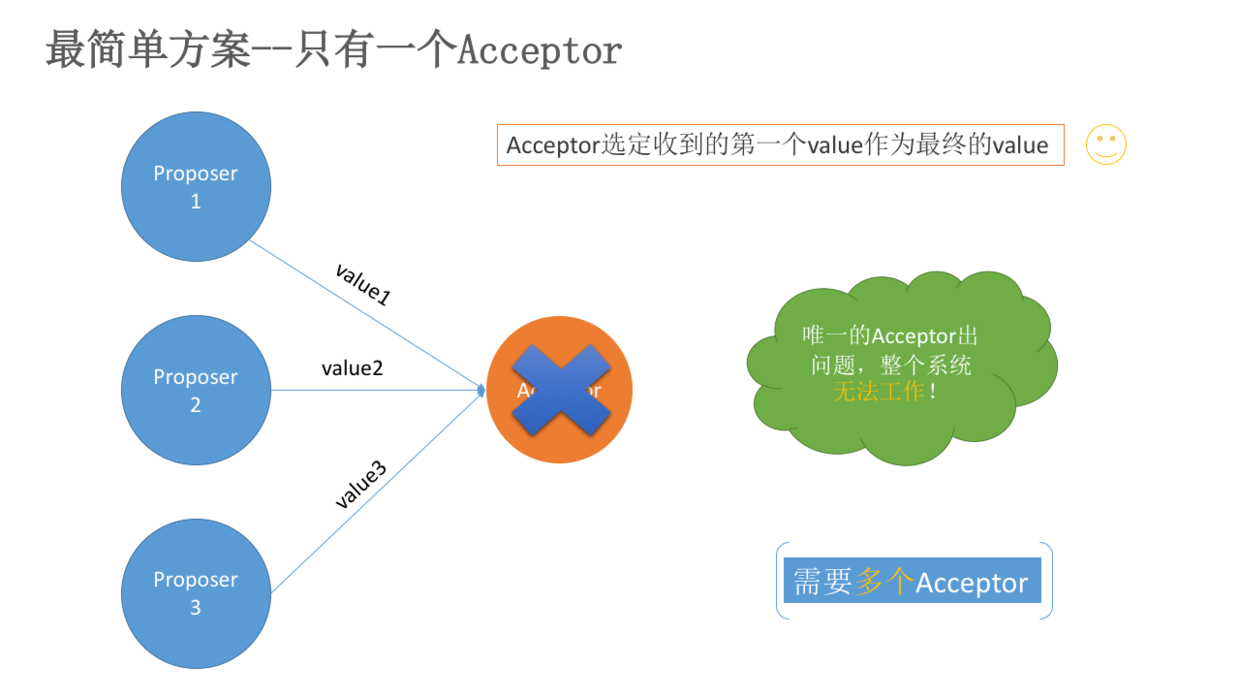
三、mail 工作原理
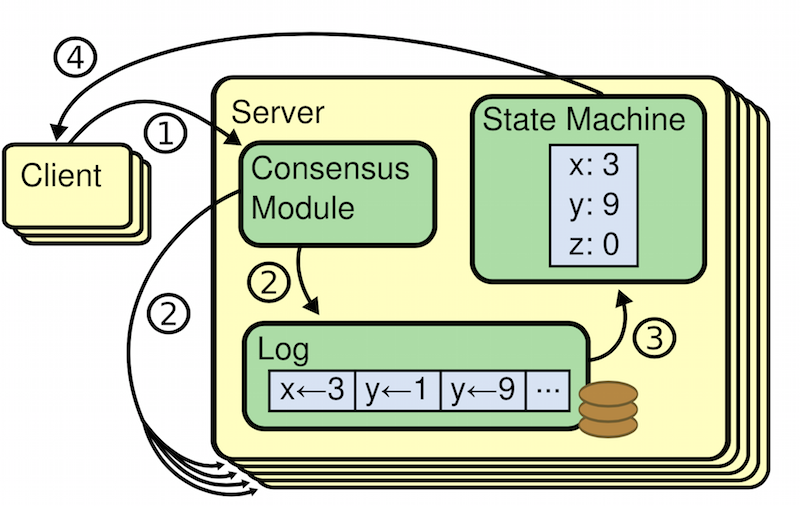
1.常规架构
如下图,
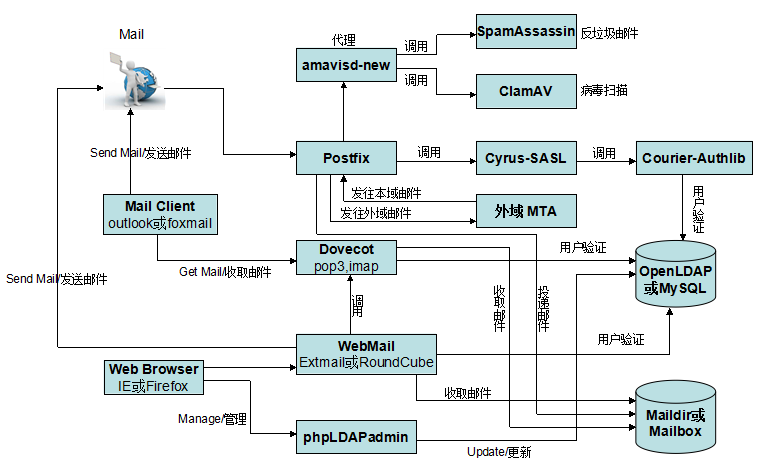
各组件具体说明
(1).常用的客户端
Mail Client:outlook,foxmail等
Web Browser:IE,Firefox,Chrome等
(2).Postfix,最常用的MTA,我们通过postfix来发送邮件
(3).Dovecot,最常用的MRA,我们通过dovecot来收发邮件
(4).amavisd-new,可以理解成一个代理,Postfix把邮件交给他,他负责联系杀毒和反垃圾
(5).SpamAssassin,防垃圾邮件,是邮件系统的基本功能,SpamAssassin,是最有名的,尤其是和Amavisd ClamAV结合起来,这是一个经得起考虑的组合
(6).ClamAV,对邮件进行病毒扫描
(7).Cyrus-SASL,认证函数库
(8).Courier-Authlib,调用mysql数据库进行认证
(9).WebMail,通过浏览器来管理收发邮件
(10).OpenLDAP或MySQL,虚拟用户或虚拟域的存放数据库
(11).Maildir或Mailbox,用来存放用户邮件,两者的区别在于maildir为每个用户单独存放邮件,mailbox是所有邮件都存放在同一文件
(12).phpLDAPadmin,管理LDAP工具,用来管理虚拟用户与虚拟域
2.具体工作流程
(1). 当邮件通过outlook或foxmail发送到服务器的25端口,postfix接受连接,它会做一些基本检查
- 发送者是否在黑名单或者实时黑名单,如果在黑名单,马上拒绝
- 是否是授权用户,是授权可以进行转发
- 接收者是否是服务器的用户,在这里postfix调用Cyrus-SASL认证函数库,并通过Courier-Authlib去mysql数据中验证用户,如果不是,马上拒绝
- 如果我们启用了灰名单,会进行判断是否会拒绝邮件或者接收
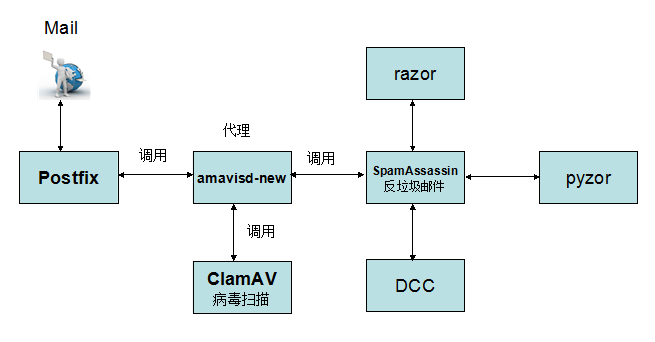
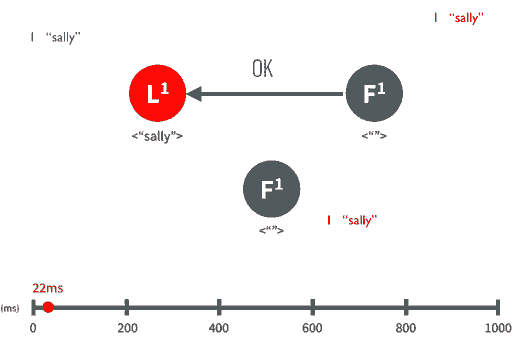
(2).postfix 把邮件通过10024端口交给amavis来处理,注意amavis,只会检查邮件而不会丢弃或者拒绝邮件(如上图)
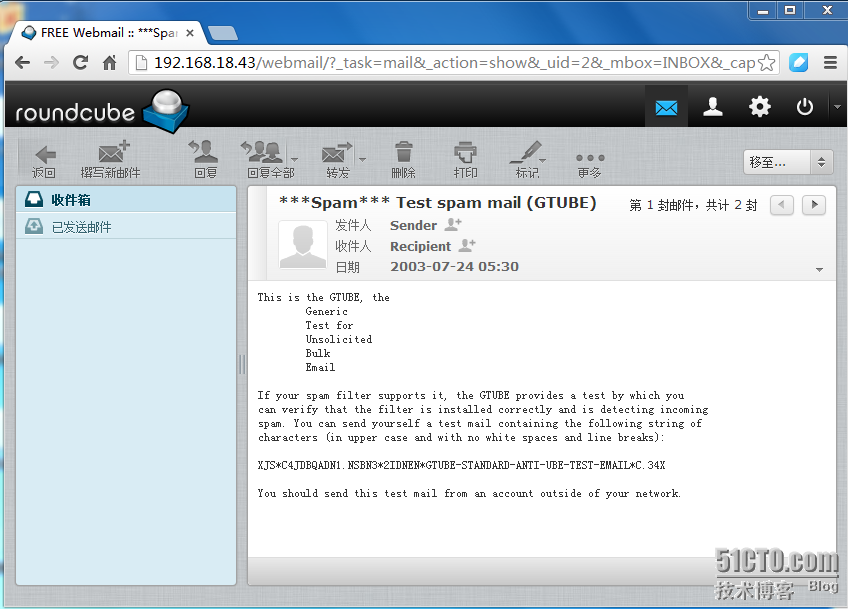
(3).amavis调用SpamAssassin检查邮件是否是spam,如果SpamAssassin认为邮件是垃圾邮件,会给邮件打上标记spam(如下图)
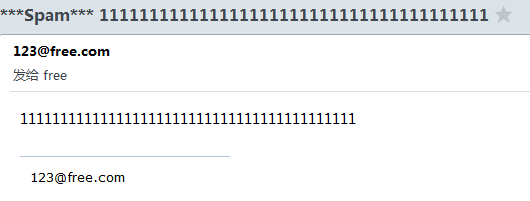
(注:大家会看到,只会给邮件打上spam标记,我们还是可以收到这个邮件的)
(4).amavis调用ClamAV,看邮件是否含有病毒
(5).amavis把检查完的邮件,通过10025端口重新把邮件交回给postfix
(6).postfix把邮件交给LDA(local delivery agent),LDA是负责本地邮件投放到用户的邮箱,postfix默认使用 procmail 投递邮件(我们也可以使用其它投递代理如,maildrop)到 用户的邮箱并以maildir的方式存放在硬盘上
(7).用户使用邮件客户端,通过pop3或imap协议进行连接并管理邮件,webmail 是通过imap的方式来读取或管理邮件
总结,从上面的工作流程我们可以看到用Cyrus-SASL,Courier-authlib,Maildrop太麻烦了。一大堆组件,邮件系统本来就很杂。我以能简单则简单的原则进行了精简而且效率更高,Dovecot目前已经实现了SASL,而且Dovecot的SASL能够自动CACHE查询结果,这个是比较好的。并且Dovecot还可以当LDA使用。而Postfix也支持Dovecot的SASL验证。Postfix可以直接使用Dovecot的后台认证,不需要分开配置。(如果使用Courier,我们必须安装配置额外的认证软件,比如Saslauthd,配置这个,会是一个恶梦,如果出现问题,很难排错),并且Dovecot,可以很方便实现磁盘配额的功能。Dovecot作为Courier的可替换组件,Dovecot在磁盘读写量上比Courier减少25%左右,内存占用也比Courier节省10%到70%不等。好了,说了这么多下面我们来看一下,我们的精简架构!
3.精简架构
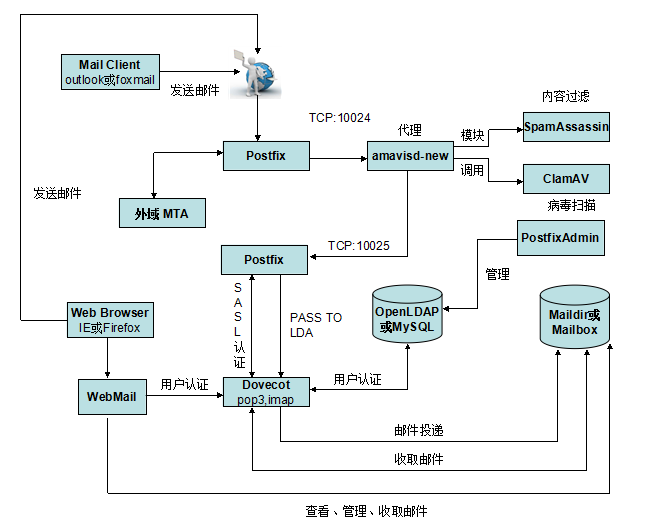
经过与上面的对比我们明显看到简单了许多,嘿嘿!下面我们说一下具体的工作流程,
(1).当邮件发送到服务器的25端口,postfix接受连接,它会做一些基本检查
- 发送者是否在黑名单或者实时黑名单,如果在黑名单,马上拒绝
- 是否是授权用户,是授权用户可以进行转发
- 接收者是否是服务器的用户,Postfix通Dovecot提供的SASL进行认证,如果不是,马上拒绝
- 如果我们启用了灰名单,会进行判断是否会拒绝邮件或者接收
(2).postfix 把邮件通过10024端口交给amavis来处理,注意amavis,只会检查邮件而不会丢弃或者拒绝邮件
(3).amavis调用SpamAssassin检查邮件是否是spam,如果SpamAssassin认为邮件是垃圾邮件,会给邮件打上标记spam(同上)
(4).amavis调用ClamAV,看邮件是否含有病毒
(5).amavis把检查完的邮件,通过10025端口重新把邮件交回给postfix
(6).postfix把邮件交给LDA(local delivery agent),LDA是负责本地邮件投放到用户的邮箱,(我们这里使用dovecot提供的LDA功能,而不是postfix提供的LDA)邮件会进入用户的邮箱,Dovecot会执行用户设置的filter,也就是Dovecot通过调用Sieve,放到相关的文件夹
(7).Dovecot 把邮件以maildir的方式存放在硬盘上。
(8).用户使用邮件客户端,通过pop3或imap协议进行连接。Webmail(RoundCubeMail),是通过imap的方式来读取邮件。
总结,经过上面的简单说明你应该知道整个邮件系统的工作流程了,下面我们将完整的搭建这套企业级的邮件系统!^_^……
四、安装前的准备工作
1.关闭防火墙与SELinux
[root@mail ~]# service iptables stop
iptables:清除防火墙规则: [确定]
iptables:将链设置为政策 ACCEPT:filter [确定]
iptables:正在卸载模块: [确定]
[root@mail ~]# service ip6tables stop
ip6tables:清除防火墙规则: [确定]
ip6tables:将 chains 设置为 ACCEPT 策略:filter [确定]
:正在卸载模块: [确定]
[root@mail ~]# chkconfig iptables off
[root@mail ~]# chkconfig ip6tables off
[root@mail ~]# vim /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of these two values:
# targeted - Targeted processes are protected,
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
[root@mail ~]# reboot
2.修改主机名
[root@mail ~]# vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=mail.free.com
[root@mail ~]# reboot
3.下载并安装yum源
(1).163的yum源
(2).rpmforge软件仓库
[root@mail ~]# wget http://mirrors.163.com/.help/CentOS6-Base-163.repo
[root@mail ~]# wget http://pkgs.repoforge.org/rpmforge-release/rpmforge-release-0.5.2-2.el6.rf.x86_64.rpm
[root@mail ~]# ls
anaconda-ks.cfg CentOS6-Base-163.repo install.log install.log.syslog rpmforge-release-0.5.2-2.el6.rf.x86_64.rpm
(3).备份原有的yum源
[root@mail ~]# cd /etc/yum.repos.d/
[root@mail yum.repos.d]# ls
CentOS-Base.repo CentOS-Debuginfo.repo CentOS-Media.repo CentOS-Vault.repo
[root@mail yum.repos.d]# mkdir backup
[root@mail yum.repos.d]# mv CentOS-* backup/
[root@mail yum.repos.d]# ls
backup
[root@mail yum.repos.d]#
(4). 增加新的yum源
[root@mail ~]# cp CentOS6-Base-163.repo /etc/yum.repos.d/
[root@mail ~]# rpm -ivh rpmforge-release-0.5.2-2.el6.rf.x86_64.rpm
warning: rpmforge-release-0.5.2-2.el6.rf.x86_64.rpm: Header V3 DSA/SHA1 Signature, key ID 6b8d79e6: NOKEY
Preparing... ########################################### [100%]
1:rpmforge-release ########################################### [100%]
[root@mail ~]# ll /etc/yum.repos.d/
总用量 24
drwxr-xr-x 2 root root 4096 7月 10 22:00 backup
-rw-r--r-- 1 root root 2006 7月 10 22:01 CentOS6-Base-163.repo
-rw-r--r-- 1 root root 739 11月 13 2010 mirrors-rpmforge
-rw-r--r-- 1 root root 717 11月 13 2010 mirrors-rpmforge-extras
-rw-r--r-- 1 root root 728 11月 13 2010 mirrors-rpmforge-testing
-rw-r--r-- 1 root root 1113 11月 13 2010 rpmforge.repo
[root@mail ~]#
(5).清理yum缓存并更新系统
[root@mail ~]# yum clean all
Loaded plugins: fastestmirror
Cleaning repos: base extras rpmforge updates
Cleaning up Everything
Cleaning up list of fastest mirrors
[root@mail ~]# yum update
4.创建一个vmail用户,用作管理虚拟邮箱的文件夹
useradd -u 2000 -d /var/vmail -m -s /sbin/nologin vmail
五、安装并配置LAMP环境
说明:最新的PostfixAdmin2.3.6+Roundcubemail0.92的PHP环境要求是最低是PHP5.2,我这里RPM安装的是5.3.3
1.安装LAMP环境
[root@mail ~]#yum -y install httpd mysql mysql-devel mysql-server php php-pecl-Fileinfo php-mcrypt php-devel php-mysql php-common php-mbstring php-gd php-imap php-ldap php-odbc php-pear php-xml php-xmlrpc pcre pcre-devel
2.整合Apache与PHP
[root@mail ~]# vim /etc/httpd/conf/httpd.conf
#增加下面现行
AddType application/x-httpd-php .php #apache解析php程序
PHPIniDir "/etc/php.ini" #指定php.ini配置文件路径
#修改这一行增加index.php
DirectoryIndex index.php index.html index.html.var
#修改apache运行的用户和组
User vmail
Group vmail
3.测试
[root@mail ~]# vim /var/www/html/index.php
<?
phpinfo();
?>
[root@mail ~]# service httpd start
正在启动 httpd:httpd: Could not reliably determine the server's fully qualified domain name, using mail.free.com for ServerName
[确定]
[root@mail ~]#
注:会有个警告
[root@mail ~]# vim /etc/httpd/conf/httpd.conf
#增加一行
ServerName localhost:80
[root@mail ~]# service httpd restart #重新启动不会再有警告
停止 httpd: [确定]
正在启动 httpd: [确定]
[root@mail html]# chkconfig httpd on #加入开机自启动
[root@mail html]# chkconfig httpd --list
httpd 0:关闭 1:关闭 2:启用 3:启用 4:启用 5:启用 6:关闭
[root@mail html]#
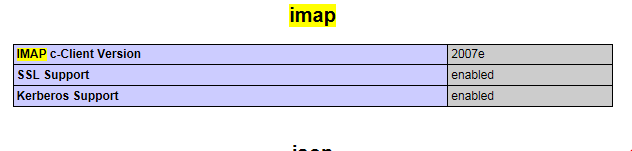
测试效果如下,
看到这个图说明LAMP环境安装成功了,嘿嘿!顺便可以看一下imap这个很重要,嘿嘿!
六、安装并配置postfixadmin
1.查看所需软件
[root@mail ~]# ll
总用量 12804
-rw-------. 1 root root 970 6月 20 05:03 anaconda-ks.cfg
-rw-r--r-- 1 root root 2006 9月 1 2011 CentOS6-Base-163.repo
-rw-r--r--. 1 root root 15709 6月 20 05:03 install.log
-rw-r--r--. 1 root root 4178 6月 20 05:01 install.log.syslog
-rw-r--r-- 1 root root 7728693 7月 7 18:48 phpMyAdmin-4.0.4.1-all-languages.zip
-rw-r--r-- 1 root root 1597001 7月 7 12:56 postfixadmin-2.3.6.tar.gz
-rw-r--r-- 1 root root 3735505 7月 7 12:57 roundcubemail-0.9.2.tar.gz
-rw-r--r-- 1 root root 12700 11月 13 2010 rpmforge-release-0.5.2-2.el6.rf.x86_64.rpm
[root@mail ~]#
2.解压并修改文件名
[root@mail ~]# tar xf postfixadmin-2.3.6.tar.gz -C /var/www/html/
[root@mail ~]# cd /var/www/html/
[root@mail html]# ls
index.php postfixadmin-2.3.6
[root@mail html]# mv postfixadmin-2.3.6 postfixadmin
[root@mail html]# ls
index.php postfixadmin
[root@mail html]#
3.配置并测试
[root@mail html]# cd postfixadmin/
#修改前先备份一下配置文件
[root@mail postfixadmin]# cp config.inc.php config.inc.php.bak
[root@mail postfixadmin]# cp setup.php setup.php.bak
[root@mail postfixadmin]# vim config.inc.php
#找到下面几行并修改
$CONF['configured'] = true;
$CONF['database_type'] = 'mysql';
$CONF['database_host'] = 'localhost';
$CONF['database_user'] = 'postfix';
$CONF['database_password'] = 'postfix';
$CONF['database_name'] = 'postfix';
$CONF['admin_email'] = 'postmaster@free.com';
$CONF['encrypt'] = 'dovecot:CRAM-MD5';
$CONF['dovecotpw'] = "/usr/bin/doveadm pw";
$CONF['domain_path'] = 'YES';
$CONF['domain_in_mailbox'] = 'NO';
$CONF['aliases'] = '1000';
$CONF['mailboxes'] = '1000';
$CONF['maxquota'] = '1000';
$CONF['fetchmail'] = 'NO';
$CONF['quota'] = 'YES';
$CONF['used_quotas'] = 'YES';
$CONF['new_quota_table'] = 'YES';
4.为postfixadmin创建Mysql数据库与权限
[root@mail html]# service mysqld start
[root@mail html]# chkconfig mysqld on #加入开机自启动
[root@mail html]# chkconfig mysqld --list
mysqld 0:关闭 1:关闭 2:启用 3:启用 4:启用 5:启用 6:关闭
[root@mail html]#
[root@mail ~]# mysql
mysql> create database postfix;
mysql> grant all on postfix.* to postfix@'localhost' identified by 'postfix';
mysql> flush privileges;
测试一下能不能登录,
[root@mail html]# mysql -upostfix -ppostfix
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.1.69 Source distribution
Copyright (c) 2000, 2013, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| postfix |
| test |
+--------------------+
3 rows in set (0.00 sec)
mysql>
测试成功可能登录!
5.修改所有者与所有组
[root@mail html]# chown -R vmail.vmail postfixadmin/
[root@mail html]# ll
总用量 8
-rw-r--r-- 1 root root 18 7月 10 22:18 index.php
drwxrwxr-x 14 vmail vmail 4096 7月 10 22:57 postfixadmin
[root@mail html]#
6.具体配置过程如下图
(1).http://192.168.18.187/postfixadmin/setup.php
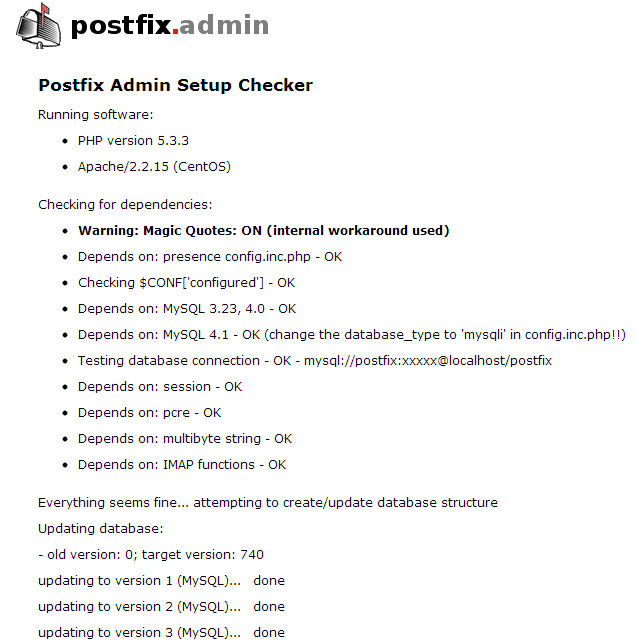
注:检查PHP环境,并初始化数据库
(2).创建设置密码并修改配置文件(我这里的密码是123456)
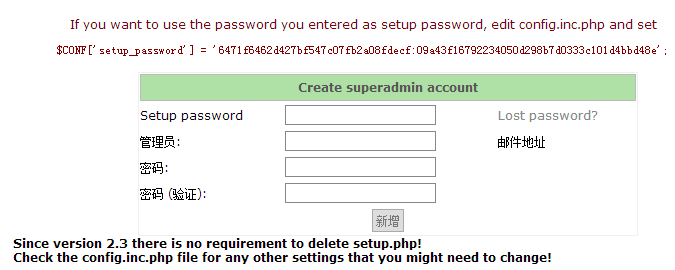
[root@mail postfixadmin]# vim config.inc.php
$CONF['setup_password'] = '6471f6462d427bf547c07fb2a08fdecf:09a43f1679223
4050d298b7d0333c101d4bbd48e';
(3).创建管理员密码
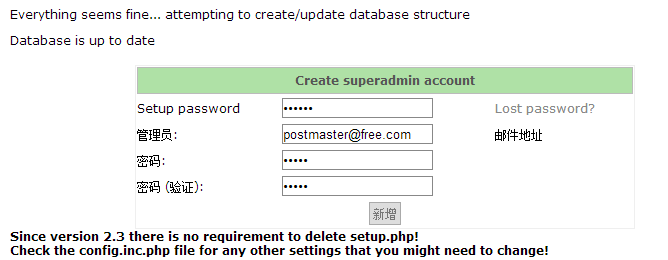
先输入你刚才设置的密码,我这里是123456,然后输入管理员邮箱,我管理员密码!

出现错误,说没有dovecotpw,是因为我们还没安装dovecot,我们这里先来安装一下dovecot,后面再进行配置!
[root@mail postfixadmin]# yum install -y dovecot dovecot-devel dovecot-mysql
[root@mail postfixadmin]# chkconfig dovecot on #加入开机自启动
[root@mail postfixadmin]# chkconfig dovecot --list
dovecot 0:关闭 1:关闭 2:启用 3:启用 4:启用 5:启用 6:关闭
[root@mail postfixadmin]#
我们再来设置一下管理员的账户与密码,(我这里设置是postmaster@free.com 密码:admin)
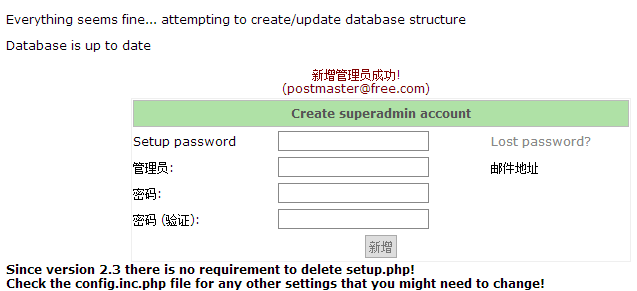
看这次设置成功,下面我们管理账户登录一下
http://192.168.18.187/postfixadmin/login.php

7.postfxiadmin不能自动创建目录,所以我们得增加自动建立目录的功能
(1).建立创建虚拟邮箱脚本,脚本名称 /usr/local/bin/maildir-creation.sh,脚本内容如下:
[root@mail ~]#vim /usr/local/bin/maildir-creation.sh
#!/bin/bash
#
HOME_DIR="/var/vmail"
USER_NAME="vmail"
GROUP_NAME="vmail"
if [ ! -d ${HOME_DIR}/$1 ] ; then
mkdir ${HOME_DIR}/$1
chown -R ${USER_NAME}.${GROUP_NAME} ${HOME_DIR}/$1
fi
mkdir ${HOME_DIR}/$1/$2
chown -R ${USER_NAME}.${GROUP_NAME} ${HOME_DIR}/$1/$2
(2).建立删除虚拟邮箱脚本,脚本名称 /usr/local/bin/maildir-deletion.sh ,脚本内容如下:
[root@mail ~]#vim /usr/local/bin/maildir-deletion.sh
#!/bin/bash
#
# vmta ALL = NOPASSWD: /usr/local/bin/maildir-deletion.sh
#
if [ $# -ne 2 ] ; then
exit 127
fi
DOMAIN="$1"
USER="$2"
HOME_DIR="/var/vmail"
USER_DIR="${HOME_DIR}/${DOMAIN}/${USER}"
TRASH_DIR="${HOME_DIR}/deleted-maildirs"
DATE=`date "+%Y%m%d_%H%M%S"`
if [ ! -d "${TRASH_DIR}/${DOMAIN}" ] ; then
mkdir -p "${TRASH_DIR}/${DOMAIN}"
fi
if [ -d "${USER_DIR}" ] ; then
mv ${USER_DIR} ${TRASH_DIR}/${DOMAIN}/${USER}-${DATE}
fi
8.建立删除目录
[root@mail ~]# mkdir /var/vmail/deleted-maildirs
[root@mail ~]# chown -R vmail.vmail /var/vmail/deleted-maildirs/
9.赋予脚本可执行权限
[root@mail ~]# chmod 750 /usr/local/bin/maildir-*
[root@mail ~]# chown vmail.vmail /usr/local/bin/maildir-*
10.配置sudo
[root@mail ~]#vim /etc/sudoers
#在 /etc/sudoers 最后增加两行
vmail ALL = NOPASSWD: /usr/local/bin/maildir-creation.sh
vmail ALL = NOPASSWD: /usr/local/bin/maildir-deletion.sh
#在/etc/sudoers 注释掉下面内容
#Defaults requiretty
:wq! #由于这个文件是只读的,所以得强制保存并退出
11.修改postfixadmin的相关文件
[root@mail ~]# cd /var/www/html/postfixadmin/
[root@mail postfixadmin]# vim create-mailbox.php
修改create-mailbox.php 文件,229行内容应该是:
db_log ($SESSID_USERNAME, $fDomain, 'create_mailbox', "$fUsername");
在该行前面增加下面一行,
system("sudo /usr/local/bin/maildir-creation.sh $fDomain ".$_POST['fUsername']);
[root@mail postfixadmin]# vim delete.php
修改delete.php 文件,146行内容应该是,
db_log ($SESSID_USERNAME, $fDomain, 'delete_mailbox', $fDelete);
在该行下面增加下面4行,
$userarray=explode("@",$fDelete);
$user=$userarray[0];
$domain=$userarray[1];
system("sudo /usr/local/bin/maildir-deletion.sh $domain $user");
好了至此postfixadmin配置全部完成,^_^……
七、安装并配置phpmyadmin
1.解压并重命令
[root@mail ~]# unzip phpMyAdmin-4.0.4.1-all-languages.zip
[root@mail ~]# mv phpMyAdmin-4.0.4.1-all-languages /var/www/html/
[root@mail ~]# cd /var/www/html/
[root@mail html]# ls
index.php phpMyAdmin-4.0.4.1-all-languages postfixadmin
[root@mail html]# mv phpMyAdmin-4.0.4.1-all-languages phpmyadmin
[root@mail html]# ls
index.php phpmyadmin postfixadmin
[root@mail html]#
2.修改配置文件
[root@mail html]# cd phpmyadmin/
[root@mail phpmyadmin]# cp config.sample.inc.php config.inc.php
[root@mail phpmyadmin]#
3.给phpmyadmin授权
mysql> grant all on *.* to root@'localhost' identified by '123456';
Query OK, 0 rows affected (0.03 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
4.测试
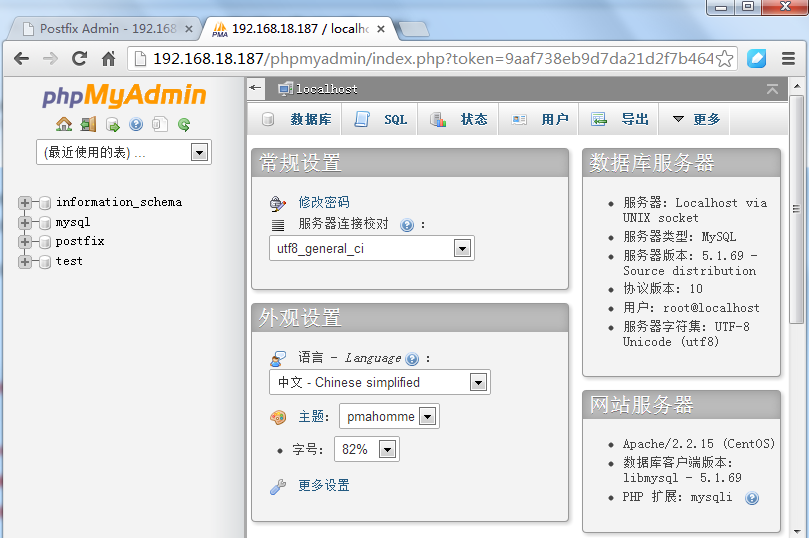
好了,登录成功,现在我们就可以用phpmyadmin来管理mysql数据库了,嘿嘿!
八、配置postfix邮件发送代理
注:Postfix用CentOS6.4系统自带的,因为CentOS6.4里面的postfix包已经支持mysql
1.查看postfix版本
[root@mail postfixadmin]# rpm -qa | grep postfix
postfix-2.6.6-2.2.el6_1.x86_64
2.配置postfix
[root@mail ~]# vim /etc/postfix/main.cf
#基本配置
myhostname = mail.free.com
mydomain = free.com
myorigin = $mydomain
inet_interfaces = all
mynetworks_style = host
mynetworks = 192.168.18/24, 127.0.0.0/8
#虚拟域名配置
virtual_mailbox_domains = proxy:mysql:/etc/postfix/mysql_virtual_domains_maps.cf
virtual_alias_maps = proxy:mysql:/etc/postfix/mysql_virtual_alias_maps.cf
virtual_mailbox_maps = proxy:mysql:/etc/postfix/mysql_virtual_mailbox_maps.cf
# Additional for quota support
virtual_create_maildirsize = yes
virtual_mailbox_extended = yes
virtual_mailbox_limit_maps = mysql:/etc/postfix/mysql_virtual_mailbox_limit_maps.cf
virtual_mailbox_limit_override = yes
virtual_maildir_limit_message = Sorry, this user has exceeded their disk space quota, please try again later.
virtual_overquota_bounce = yes
#Specify the user/group that owns the mail folders. I'm not sure if this is strictly necessary when using Dovecot's LDA.
virtual_uid_maps = static:2000
virtual_gid_maps = static:2000
#Specifies which tables proxymap can read: http://www.postfix.org/postconf.5.html#proxy_read_maps
proxy_read_maps = $local_recipient_maps $mydestination $virtual_alias_maps $virtual_alias_domains $virtual_mailbox_maps $virtual_mailbox_domains $relay_recipient_maps $relay_domains $canonical_maps $sender_canonical_maps $recipient_canonical_maps $relocated_maps $transport_maps $mynetworks $virtual_mailbox_limit_maps
[root@mail ~]# postconf #检查配置文件是否有错误
3.创建Mysql脚本(注意用户名和密码、DBNAME,我这里全是postfix)
(1).创建/etc/postfix/mysql_virtual_domains_maps.cf文件
[root@mail ~]# vim /etc/postfix/mysql_virtual_domains_maps.cf
user = postfix
password = postfix
hosts = localhost
dbname = postfix
query = SELECT domain FROM domain WHERE domain='%s' AND active = '1'
#optional query to use when relaying for backup MX
#query = SELECT domain FROM domain WHERE domain='%s' AND backupmx = '0' AND active = '1'
(2).创建/etc/postfix/mysql_virtual_alias_maps.cf文件
[root@mail ~]# vim /etc/postfix/mysql_virtual_alias_maps.cf
user = postfix
password = postfix
hosts = localhost
dbname = postfix
query = SELECT goto FROM alias WHERE address='%s' AND active = '1'
(3).创建/etc/postfix/mysql_virtual_mailbox_maps.cf文件
[root@mail ~]# vim /etc/postfix/mysql_virtual_mailbox_maps.cf
user = postfix
password = postfix
hosts = localhost
dbname = postfix
query = SELECT CONCAT(domain,'/',maildir) FROM mailbox WHERE username='%s' AND active = '1'
(4).创建/etc/postfix/mysql_virtual_mailbox_limit_maps.cf文件
[root@mail ~]# vim /etc/postfix/mysql_virtual_mailbox_limit_maps.cf
user = postfix
password = postfix
hosts = localhost
dbname = postfix
query = SELECT quota FROM mailbox WHERE username='%s' AND active = '1'
4.SMTP 认证设定
(1).查看postfix支持的认证,默认支持dovecot
[root@mail ~]# postconf -a
cyrus
dovecot
(2).修改/etc/postfix/main.cf配置文件
[root@mail ~]#vim /etc/postfix/main.cf
#SASL SUPPORT FOR CLIENTS
# Turns on sasl authorization
smtpd_sasl_auth_enable = yes
#Use dovecot for authentication
smtpd_sasl_type = dovecot
# Path to UNIX socket for SASL
smtpd_sasl_path = /var/run/dovecot/auth-client
#Disable anonymous login. We don't want to run an open relay for spammers.
smtpd_sasl_security_options = noanonymous
#Adds support for email software that doesn't follow RFC 4954.
#This includes most versions of Microsoft Outlook before 2007.
broken_sasl_auth_clients = yes
#
smtpd_recipient_restrictions = permit_sasl_authenticated, permit_mynetworks, reject_unauth_destination
5.使用Dovecot做为投递
[root@mail ~]# vim /etc/postfix/main.cf
# TRANSPORT MAP
virtual_transport = dovecot
dovecot_destination_recipient_limit = 1
#修改master.cf文件
[root@mail ~]# vim /etc/postfix/master.cf
#在最后增加这两行,注意flags前面有两个空格,不然会报错
dovecot unix - n n - - pipe,
flags=DRhu user=vmail:vmail argv=/usr/libexec/dovecot/dovecot-lda -f ${sender} -d ${recipient}
九、安装并配置dovecot邮件检索代理
说明:dovecot 1.X 与 dovecot 2.X配置文件的区别,1.X所以的配置都在同文件中而2.X是多个文件存放的(/etc/dovecot/dovecot.conf 和 /etc/dovecot/conf.d/),所有2.X配置文件比较分散,我把需要修改的配置文件的内容列出来
1.修改dovecot配置文件
(1).修改/etc/dovecot/dovecot.conf #主配置文件
[root@mail ~]# vim /etc/dovecot/dovecot.conf
protocols = imap pop3
listen = *
dict {
quota = mysql:/etc/dovecot/dovecot-dict-sql.conf.ext
}
!include conf.d/*.conf
(2).修改/etc/dovecot/conf.d/10-auth.conf
[root@mail ~]# vim /etc/dovecot/conf.d/10-auth.conf
disable_plaintext_auth = no
auth_mechanisms = plain login cram-md5
!include auth-sql.conf.ext
(3).修改/etc/dovecot/conf.d/10-mail.conf
[root@mail ~]# vim /etc/dovecot/conf.d/10-mail.conf
mail_location = maildir:%hMaildir
mbox_write_locks = fcntl
(4).修改/etc/dovecot/conf.d/10-master.conf
[root@mail ~]# vim /etc/dovecot/conf.d/10-master.conf
service imap-login {
inet_listener imap {
}
inet_listener imaps {
}
}
service pop3-login {
inet_listener pop3 {
}
inet_listener pop3s {
}
}
service lmtp {
unix_listener lmtp {
}
}
service imap {
}
service pop3 {
}
service auth {
unix_listener auth-userdb {
mode = 0600
user = vmail
group = vmail
}
#新加下面一段,为smtp做认证
unix_listener auth-client {
mode = 0600
user = postfix
group = postfix
}
}
service auth-worker {
}
service dict {
unix_listener dict {
mode = 0600
user = vmail
group = vmail
}
}
(5).修改/etc/dovecot/conf.d/15-lda.conf
[root@mail ~]# vim /etc/dovecot/conf.d/15-lda.conf
protocol lda {
mail_plugins = quota
postmaster_address = postmaster@free.com #管理员邮箱
}
(6).修改/etc/dovecot/conf.d/20-imap.conf
[root@mail ~]# vim /etc/dovecot/conf.d/20-imap.conf
protocol imap {
mail_plugins = quota imap_quota
}
(7).修改/etc/dovecot/conf.d/20-pop3.conf
[root@mail ~]# vim /etc/dovecot/conf.d/20-pop3.conf
protocol pop3 {
pop3_uidl_format = %08Xu%08Xv
mail_plugins = quota
}
(8).修改/etc/dovecot/conf.d/90-quota.conf
[root@mail ~]# vim /etc/dovecot/conf.d/90-quota.conf
plugin {
quota_rule = *:storage=1G
}
plugin {
}
plugin {
quota = dict:User quota::proxy::quota
}
plugin {
}
(9).增加/etc/dovecot/dovecot-sql.conf.ext
[root@mail ~]# vim /etc/dovecot/dovecot-sql.conf.ext
driver = mysql
connect = host=localhost dbname=postfix user=postfix password=postfix
default_pass_scheme = CRAM-MD5
user_query = SELECT CONCAT('/var/vmail/', maildir) AS home, 2000 AS uid, 2000 AS gid, CONCAT('*:bytes=', quota) as quota_rule FROM mailbox WHERE username = '%u' AND active='1'
password_query = SELECT username AS user, password, CONCAT('/var/vmail/', maildir) AS userdb_home, 2000 AS userdb_uid, 2000 AS userdb_gid, CONCAT('*:bytes=', quota) as userdb_quota_rule FROM mailbox WHERE username = '%u' AND active='1'
(10).增加/etc/dovecot/dovecot-dict-sql.conf.ext
[root@mail ~]# vim /etc/dovecot/dovecot-dict-sql.conf.ext
connect = host=localhost dbname=postfix user=postfix password=postfix
map {
pattern = priv/quota/storage
table = quota2
username_field = username
value_field = bytes
}
map {
pattern = priv/quota/messages
table = quota2
username_field = username
value_field = messages
}
2.重新启动服务
[root@mail ~]# service postfix restart
关闭 postfix: [确定]
启动 postfix: [确定]
[root@mail ~]# service dovecot restart
停止 Dovecot Imap: [失败]
正在启动 Dovecot Imap: [确定]
至此dovecot配置全部完成,^_^ ……
十、测试SMTP与POP3服务
1.postfixadmin创建虚拟域
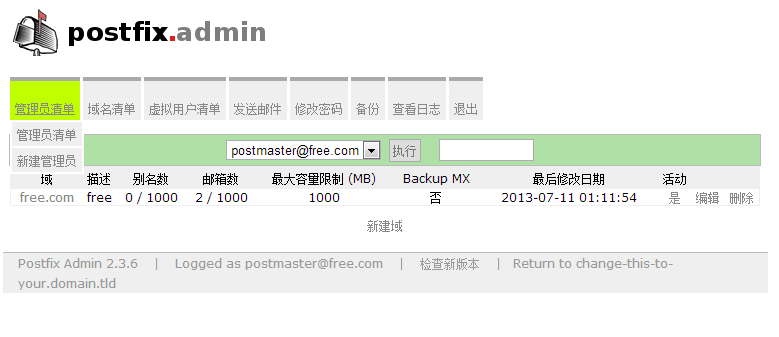
注:新建free.com测试域!
2.postfixadmin创建测试箱
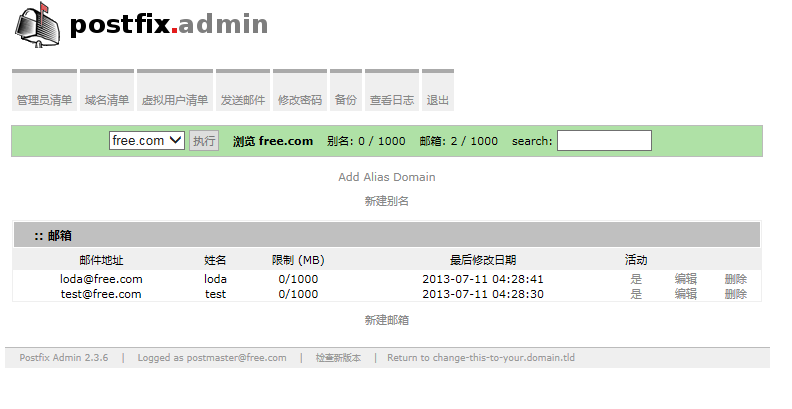
注:新建test@free.com和loda@free.com两个测试邮箱!
3.测试连接25端口
[root@mail ~]# telnet localhost 25
Trying ::1...
Connected to localhost.
Escape character is '^]'.
220 mail.free.com ESMTP Postfix
ehlo free.com
250-mail.free.com
250-PIPELINING
250-SIZE 10240000
250-VRFY
250-ETRN
250-AUTH PLAIN LOGIN CRAM-MD5
250-AUTH=PLAIN LOGIN CRAM-MD5
250-ENHANCEDSTATUSCODES
250-8BITMIME
250 DSN
quit
221 2.0.0 Bye
Connection closed by foreign host.
[root@mail ~]#
注:连接成功!
4.测试连接110端口
[root@mail ~]# telnet localhost 110
Trying ::1...
telnet: connect to address ::1: Connection refused
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
+OK Dovecot ready.
user 123@free.com
+OK
pass 123456
+OK Logged in.
quit
+OK Logging out.
Connection closed by foreign host.
[root@mail ~]#
注:可以看到,认证成功并登录成功!
5.查看自动创建的邮箱
[root@mail ~]# cd /var/vmail/
[root@mail vmail]# ll
总用量 8
drwxr-xr-x 2 vmail vmail 4096 7月 11 00:07 deleted-maildirs
drwx------ 3 vmail vmail 4096 7月 11 01:17 free.com
[root@mail vmail]# cd free.com/
[root@mail free.com]# ls
123
[root@mail free.com]#
注:已自动创建脚本,说明我们上面的脚本执行成功!
6.foxmail客户端测试收发邮件
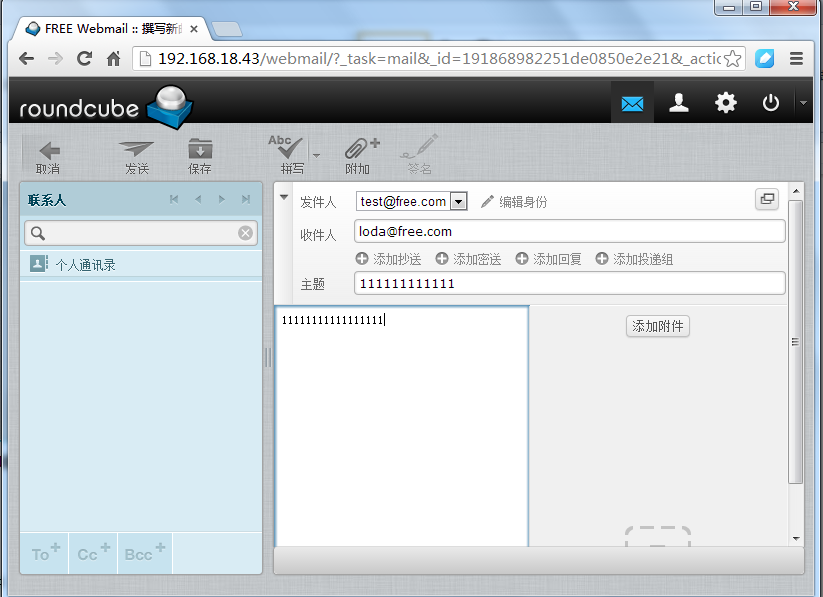
如图,test@free.com 发给 loda@free.com 邮件
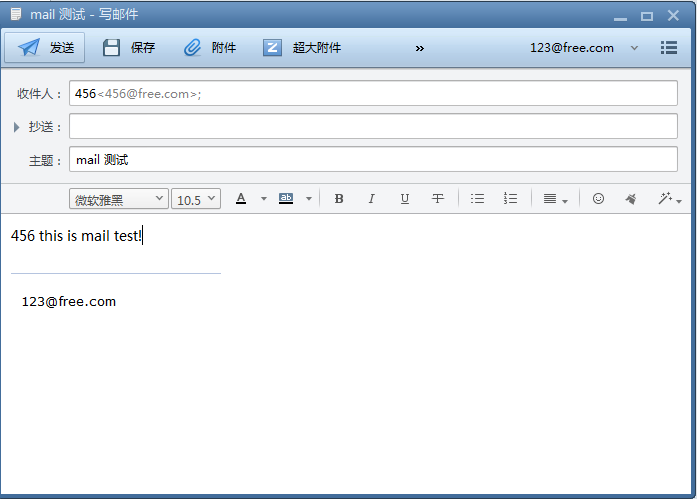
loda@free.com 成功收到邮件!
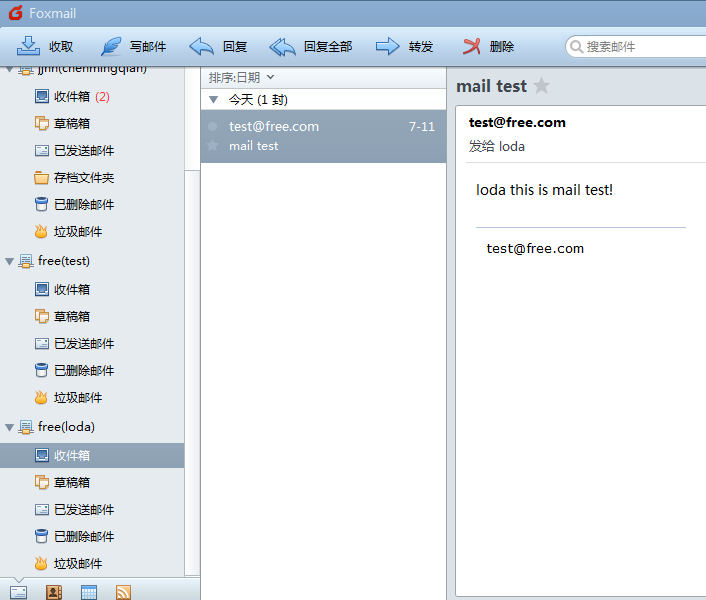
详细内容如下,
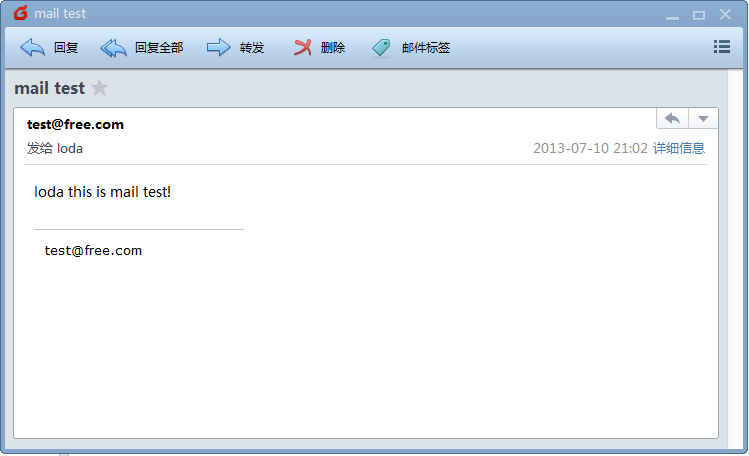
测试成功能发能收!
7.问题说明
如下图,当我们执行postfixadmin的备份,会出现以下警告,并不能实现备份!
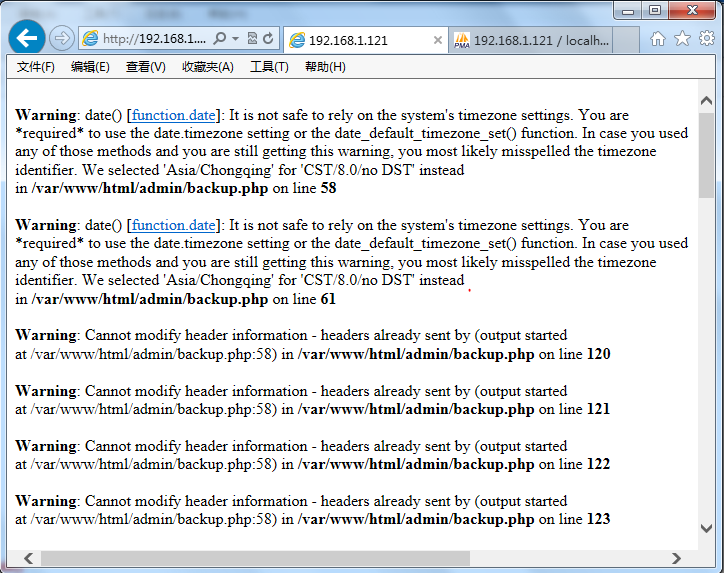
从上图中我们可以看出,data.timezone时区问题引起的,下面我们就来解决一下!
(1).修改/var/www/html/admin/backup.php文件
[root@mail admin]# vim /var/www/html/admin/backup.php
#增加一行(如下图)
date_default_timezone_set('PRC');
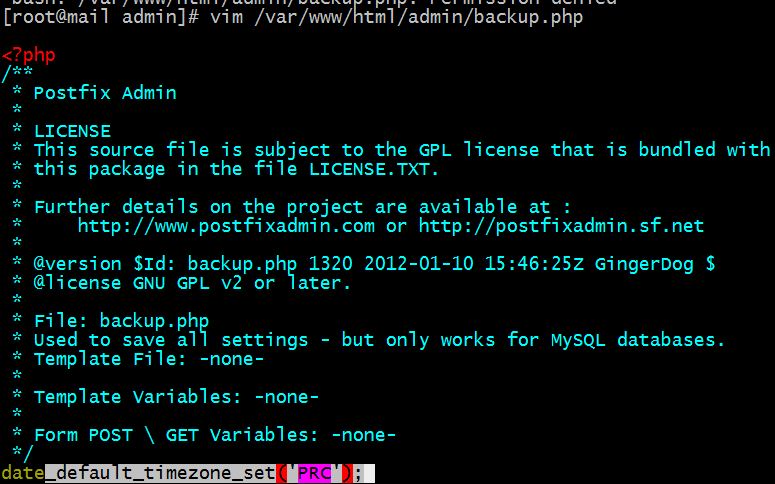
(2).效果如下
注:postfixadmin备份成功!到此一个完整的邮件系统已完成,但是为了方便的浏览和管理文件,我们下面安装一下WebMail!
十一、安装并配置WebMail(Roundcubemail)
1.解压并重命名
[root@mail ~]# tar -xf roundcubemail-0.9.2.tar.gz -C /var/www/html/
[root@mail ~]# cd /var/www/html/
[root@mail html]# ls
admin index.php phpmyadmin roundcubemail-0.9.2
[root@mail html]# mv roundcubemail-0.9.2 webmail
[root@mail html]# ls
admin index.php phpmyadmin webmail
[root@mail html]#
2.配置WebMail
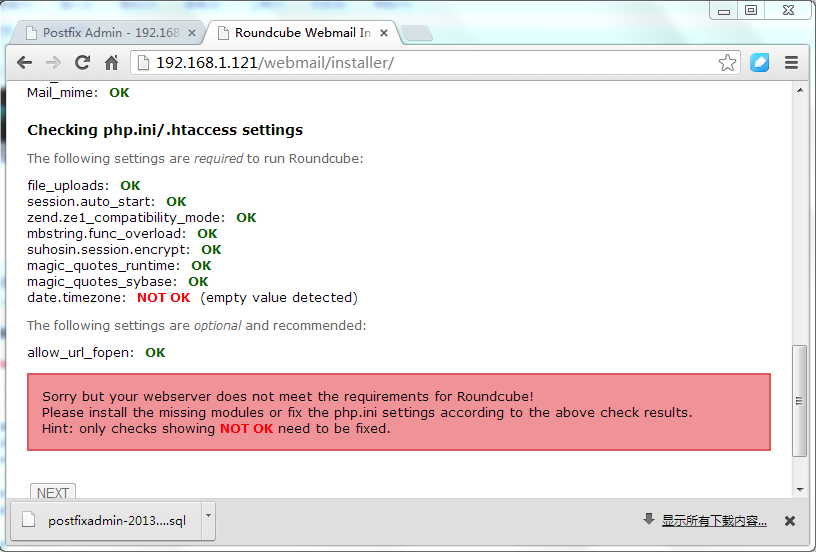
从图上可以看出date.timezone报错,下面我们来修正一下!
3.修改php.ini
[root@mail installer]# vim /etc/php.ini
date.timezone = Asia/Shanghai
4.修改apache中PHPini的位置
[root@mail installer]# vim /etc/httpd/conf/httpd.conf
PHPIniDir "/etc/php.ini"
[root@mail installer]# service httpd restart
Stopping httpd: [ OK ]
Starting httpd: [ OK ]
[root@mail installer]#
5.修改所有Web文件的所属者与所属组
[root@mail ~]# cd /var/www/html/
[root@mail html]# ll
total 16
drwxrwxr-x 14 1000 1010 4096 Jul 11 05:25 admin
-rw-r--r-- 1 root root 18 Jul 11 04:12 index.php
drwxr-xr-x 9 root root 4096 Jul 11 04:17 phpmyadmin
drwxr-xr-x 11 501 80 4096 Jun 16 23:10 webmail
[root@mail html]# chown -R vmail.vmail admin
[root@mail html]# chown -R vmail.vmail phpmyadmin
[root@mail html]# chown -R vmail.vmail webmail
[root@mail html]# ll
total 16
drwxrwxr-x 14 vmail vmail 4096 Jul 11 05:25 admin
-rw-r--r-- 1 root root 18 Jul 11 04:12 index.php
drwxr-xr-x 9 vmail vmail 4096 Jul 11 04:17 phpmyadmin
drwxr-xr-x 11 vmail vmail 4096 Jun 16 23:10 webmail
6.查看session保存位置
[root@mail html]# vim /etc/php.ini
session.save_path = "/var/lib/php/session"
7.修改session文件的所属组
[root@mail html]# cd /var/lib/php/
[root@mail php]# ll
total 4
drwxrwx--- 2 root apache 4096 Feb 22 10:56 session
[root@mail php]# chown -R .vmail session/
[root@mail php]# ll
total 4
drwxrwx--- 2 root vmail 4096 Feb 22 10:56 session
[root@mail php]#
8.效果如下
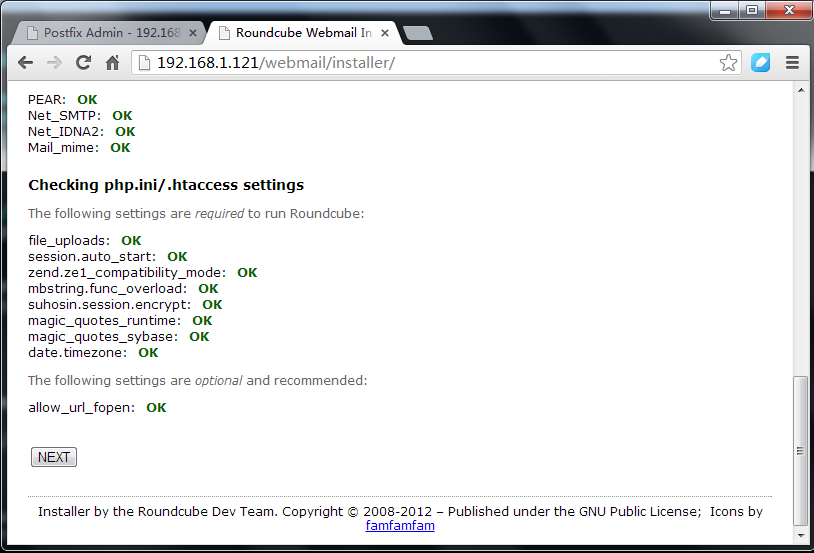
9.单击NEXT我们继续进行设置(下面是必须配置的选项)
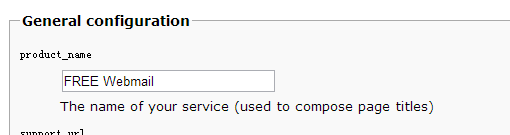
(1).配置webmail的显示名称
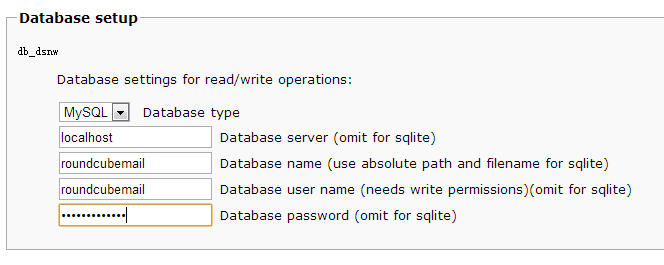
(2).配置Webmail数据库相关(我这里全部设置是,roundcubemail)
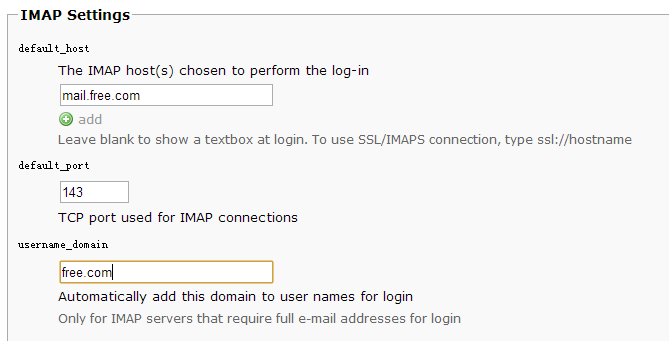
(3).配置IMAP
(4). 配置SMTP服务器
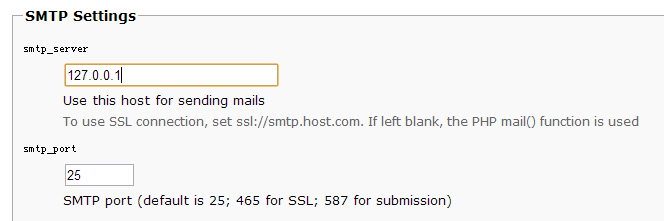
(5).配置完成效果如下,(大家可以看到我们配置好的选项都被列出来了,我们得下载两个配置文件main.inc.php和db.inc.php并上传到时服务器中)

(6).上传至服务器相关目录中
[root@mail ~]# cd /var/www/html/webmail/config/
[root@mail config]# ll
total 92
-rw-r--r-- 1 root root 2905 Jul 10 22:15 db.inc.php
-rw-r--r-- 1 vmail vmail 2893 Jun 16 23:10 db.inc.php.dist
-rw-r--r-- 1 root root 38438 Jul 10 22:15 main.inc.php
-rw-r--r-- 1 vmail vmail 38414 Jun 16 23:10 main.inc.php.dist
-rw-r--r-- 1 vmail vmail 2731 Jun 16 23:10 mimetypes.php
[root@mail config]#
(7). 给WebMail授权
mysql> CREATE DATABASE roundcubemail;
Query OK, 1 row affected (0.00 sec)
mysql> GRANT ALL PRIVILEGES ON roundcubemail.* TO roundcubemail@localhost IDENTIFIED BY 'roundcubemail';
FLUSH PRIVILEGES;Query OK, 0 rows affected (0.01 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
10.单击CONTINUE继续
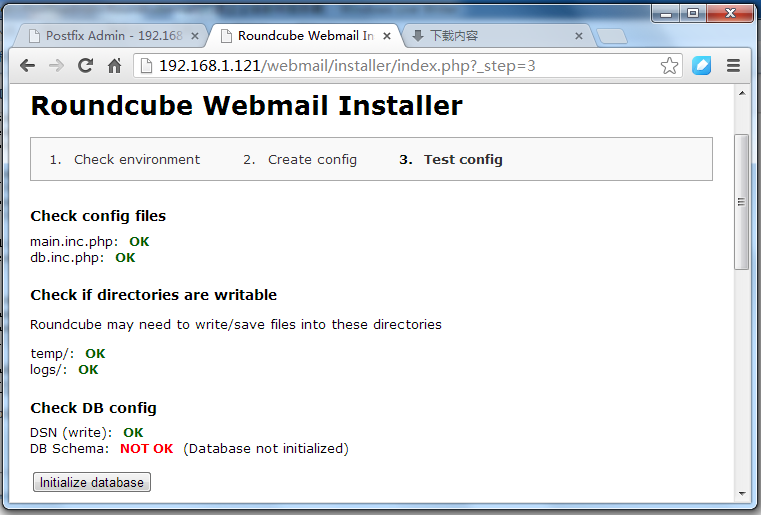
11.单击初始化数据库按钮
12.初始化完成并用phpmyadmin查看
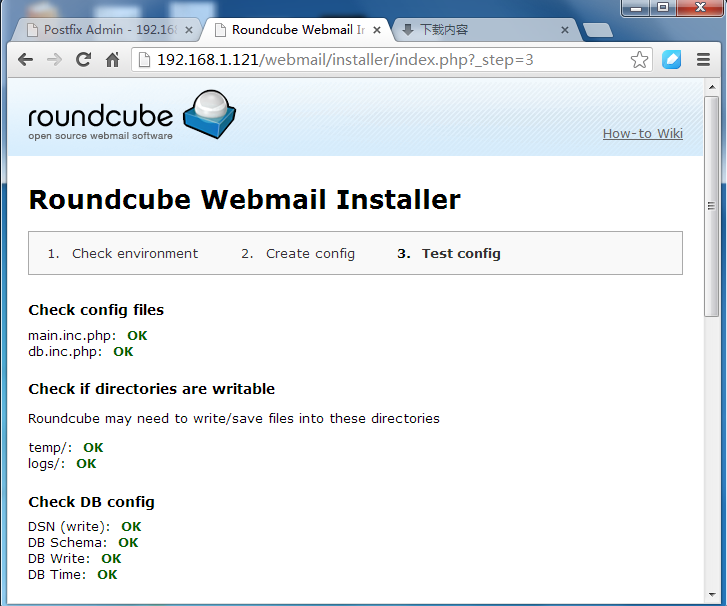
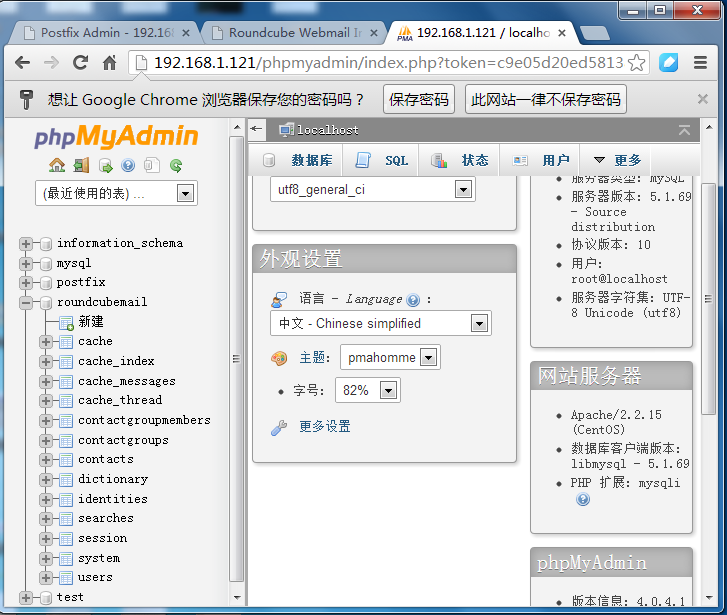
可以看到已建立好的数据库文件!^_^……
13.下面我们进行WebMail测试
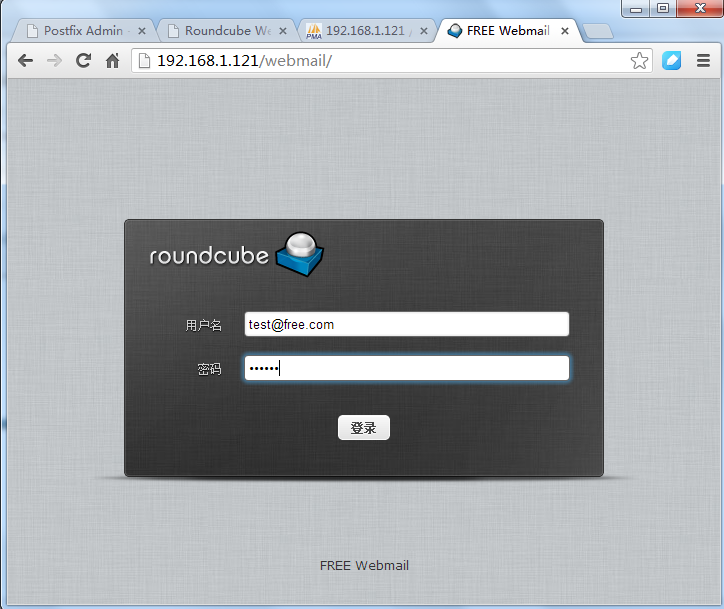
14.登录并进行收发邮件
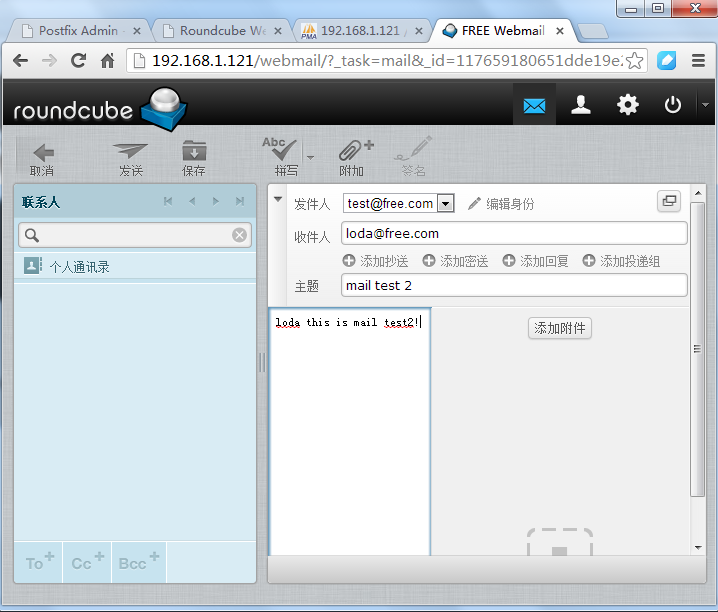
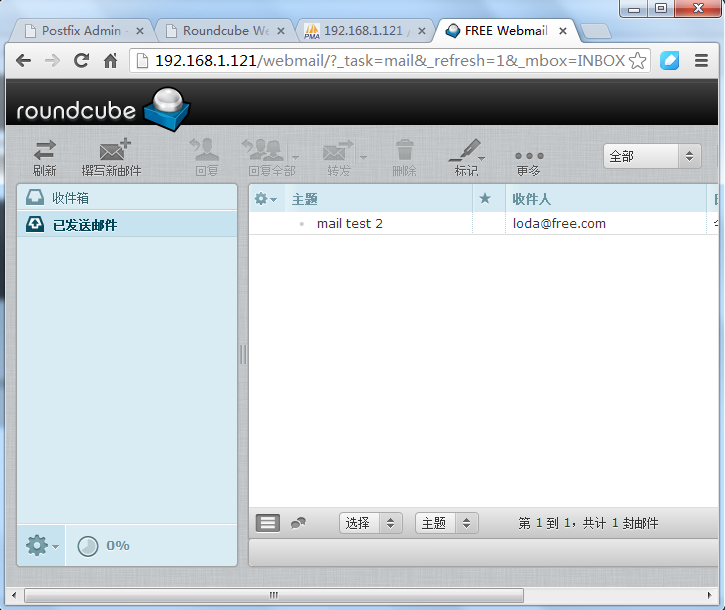
可以看到发送成功,嘿嘿!下面我们用foxmail接收一下!
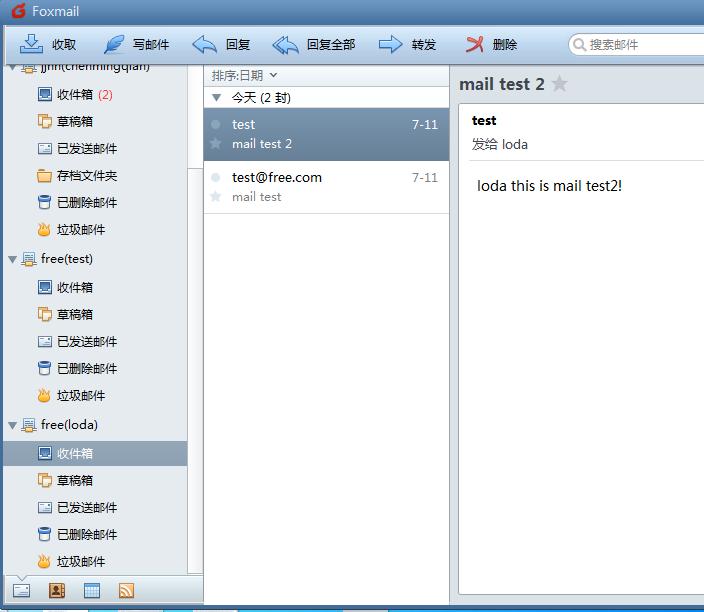
可以看到我们成功的收到了这封邮件测试成功!至些WebMail安装成功,下面我们就得说反垃圾邮件和邮件杀毒了,嘿嘿!
说明:由于整个mail邮件系统配置复杂,文字与图片较多我分了两篇进行说明!下一篇博文中CentOS6.4+LAMP+Postfix+Dovecot+Postfixadmin+Roundcubemail 打造企业级邮件服务器 (2)我们重点讲解,
十二、安装并配置病毒扫描与垃圾邮件过滤
十三、安装并配置managesieve插件
十四、常见问题分析