一、组网结构图如下:
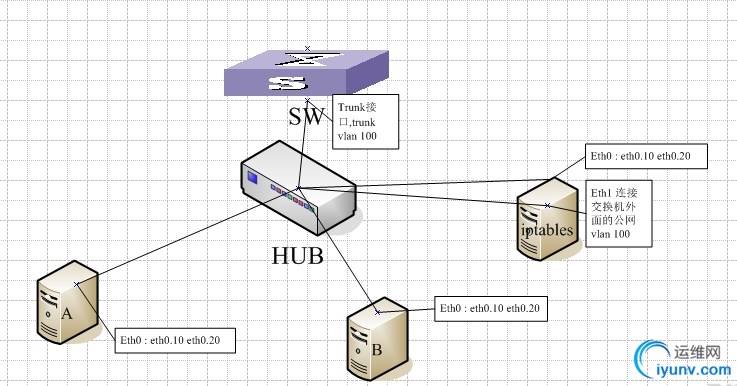
1、SW交换机和HUB
1)、交换机连接HUB的端口为trunk模式,trunk vlan100,交换机上的外网网段为10.10.100.0/24,vlan为100 ,分配iptables服务器的IP是10.10.100.100,网关是10.10.100.254;
2)、HUB是一个纯hub,不能做任何的配置。
2、服务器A
- A主机的eth0上联到HUB,把eth0划分成两个逻辑子端口eth0.10、eth0.20,eth0.10打上vlan10标签,eth0.20打上vlan20标签;
- A主机里面运行两个虚拟机VM1和VM2;
- 两台虚拟机在不同的网段,10.10.10.0/24 vlan10网关是10.10.10.254、10.10.20.0/24vlan20 网关是10.10.20.254;
- 在主机A中建立两个bridge: br10、br20 ,br10关联端口eth0.10 ,br20关联端口eth0.20,br10的IP是10.10.10.1,br20的IP是10.10.20.1
- VM1桥接到br10ip:10.10.10.11,VM2桥接到br20 ip:10.10.20.11;
3、服务器B1)、B主机的eth0上联到HUB,把eth0划分成两个逻辑子端口eth0.10、eth0.20,eth0.10打上vlan10标签,eth0.20打上vlan20标签;
2)、B主机里面运行两个虚拟机VM3和VM4;
3)、两台虚拟机在不同的网段,10.10.10.0/24 vlan10 网关是10.10.10.254、10.10.20.0/24 vlan20 网关是10.10.20.254;
4)、在主机B中建立两个bridge: br10、br20 ,br10关联端口eth0.10 ,br20关联端口eth0.20,br10的IP是10.10.10.2,br20的IP是10.10.20.2
5)、VM3桥接到br10 ip是10.10.10.12,VM2桥接到br20 ip是10.10.20.12;
4、IPtables服务器
1)、iptalbes服务器在这的作用是:让A、B服务器内的虚拟机出网nat作用、通过外网访问A、B虚拟机提供的web服务器。
2)、iptables服务器的eth0口,走虚拟机vlan10、vlan20的业务流量,所以需要通过eth0划分两个逻辑端口eth0.10、eth0.20,并且创建两个bridge:br10、br20,br10关联端口eth0.10,br20关联端口eth0.20,br10的ip地址是10.10.10.254,br20的ip地址是10.10.20.254。
3)、iptables服务器的eth1口作为外网出口接入hub,需要在eth1端口上配置IP10.10.100.100,网关配置为10.10.100.254,用vconfig命令给eth1打上vlan标签100。
5、实现需求 A、B服务器的虚拟机可以相互访问,虚拟机可以访问外网,A服务器提供的web管理界面可以通过外网访问。
二、网络层面设备配置1、交换机配置 把交换机和hub相连的端口配置为trunk端口,允许vlan 100通过。
2、服务器A的配置1)、安装vconfig包(redhat7.0一下版本默认带vconfig包)
yum install vconfig
2)、在内核加载802.1q模块
modprobe 8021q
lsmod |grep -i 8021q (查看模块是否加载)
3)、配置物理网卡
sed –i 's/ONBOOT=no/ONBOOT=yes/g' /etc/sysconfig/network-scripts/ifcfg-eth0
sed –i 's/BOOTPROTO=dhcp/BOOTPROTO=static/g'/etc/sysconfig/network-scripts/ifcfg-eth0
3)、给物理接口添加vlan并配置vlan的属性
vconfig add eth0 10
config set_flag eth0.10 1 1
vconfig add eth0 20
config set_flag eth0.20 1 1
4)、添加eth0.10、eth0.20子接口并添加配置文件
touch /etc/sysconfig/network-scripts/ifcfg-eth0.10
echo 'DEVICE=eth0.10' >> /etc/sysconfig/network-scripts/ifcfg-eth0.10
echo 'ONBOOT=yes' >> /etc/sysconfig/network-scripts/ifcfg-eth0.10
echo 'BOOTPROTO=static' >>/etc/sysconfig/network-scripts/ifcfg-eth0.10
echo 'TYPE=ethernet' >>/etc/sysconfig/network-scripts/ifcfg-eth0.10
echo 'VLAN=yes' >>/etc/sysconfig/network-scripts/ifcfg-eth0.10
echo 'BRIDGE=br10' >>/etc/sysconfig/network-scripts/ifcfg-eth0.10 #(把eth0.10加入br10)
touch /etc/sysconfig/network-scripts/ifcfg-eth0.20
echo 'DEVICE=eth0.20' >> /etc/sysconfig/network-scripts/ifcfg-eth0.20
echo 'ONBOOT=yes' >>/etc/sysconfig/network-scripts/ifcfg-eth0.20
echo 'BOOTPROTO=static' >>/etc/sysconfig/network-scripts/ifcfg-eth0.20
echo 'TYPE=ethernet' >>/etc/sysconfig/network-scripts/ifcfg-eth0.20
echo 'VLAN=yes' >>/etc/sysconfig/network-scripts/ifcfg-eth0.20
echo 'BRIDGE=br20' >>/etc/sysconfig/network-scripts/ifcfg-eth0.20 #(把eth0.20加入br20)
5)、配置bridge
touch/etc/sysconfig/network-scripts/ifcfg-br10
echo 'DEVICE=br10' >> /etc/sysconfig/network-scripts/ifcfg-br10
echo 'ONBOOT=yes' >> /etc/sysconfig/network-scripts/ifcfg-br10
echo 'BOOTPROTO=static'>> /etc/sysconfig/network-scripts/ifcfg-br10
echo 'TYPE=bridge' >>/etc/sysconfig/network-scripts/ifcfg-br10
touch/etc/sysconfig/network-scripts/ifcfg-br20
echo 'DEVICE=br10' >> /etc/sysconfig/network-scripts/ifcfg-br20
echo 'ONBOOT=yes' >> /etc/sysconfig/network-scripts/ifcfg-br20
echo 'BOOTPROTO=static'>> /etc/sysconfig/network-scripts/ifcfg-br20
echo 'TYPE=bridge' >>/etc/sysconfig/network-scripts/ifcfg-br20
6)、启动子接口和bridge接口
ifup eth0.10
ifup eth0.20
ifup br10
ifup br20
7)、给bridge接口配置IP
echo 'IPADDR=10.10.10.1' >> /etc/sysconfig/network-scripts/ifcfg-br10
echo 'NETMASK=255.255.255.0' >> /etc/sysconfig/network-scripts/ifcfg-br10
echo 'IPADDR=10.10.20.1' >> /etc/sysconfig/network-scripts/ifcfg-br20
echo 'NETMASK= 255.255.255.0' >> /etc/sysconfig/network-scripts/ifcfg-br20
8)、添加eth0.10 eth0.20到br10、br20
brctl addif br10 eth0.10
brctl addif br20 eth0.20
9)、重启网络
service network restart
10)、设置下次启动自动加载8021q 模块
echo 'VLAN=yes' >> /etc/sysconfig/network
echo 'modprobe 8021q'>>/etc/rc.local
11)、可以使用cat /proc/net/vlan/eth0.10查看eth0.10参数
3、服务器B的配置1)、安装vconfig包(redhat7.0一下版本默认带vconfig包)
yum install vconfig
2)、在内核加载802.1q模块
modprobe 8021q
lsmod |grep -i8021q (查看模块是否加载)
3)、配置物理网卡
sed –i 's/ONBOOT=no/ONBOOT=yes/g' /etc/sysconfig/network-scripts/ifcfg-eth0
sed –i 's/BOOTPROTO=dhcp/BOOTPROTO=static/g'/etc/sysconfig/network-scripts/ifcfg-eth0
3)、给物理接口添加vlan并配置vlan的属性
vconfig add eth010
config set_flageth0.10 1 1
vconfig add eth0 20
config set_flag eth0.20 1 1
4)、添加eth0.10、eth0.20子接口并添加配置文件
touch/etc/sysconfig/network-scripts/ifcfg-eth0.10
echo'DEVICE=eth0.10' >>/etc/sysconfig/network-scripts/ifcfg-eth0.10
echo'ONBOOT=yes' >>/etc/sysconfig/network-scripts/ifcfg-eth0.10
echo'BOOTPROTO=static' >> /etc/sysconfig/network-scripts/ifcfg-eth0.10
echo 'TYPE=ethernet'>> /etc/sysconfig/network-scripts/ifcfg-eth0.10
echo'VLAN=yes' >>/etc/sysconfig/network-scripts/ifcfg-eth0.10
echo'BRIDGE=br10' >>/etc/sysconfig/network-scripts/ifcfg-eth0.10 #(把eth0.10加入br10)
touch/etc/sysconfig/network-scripts/ifcfg-eth0.20
echo'DEVICE=eth0.20' >>/etc/sysconfig/network-scripts/ifcfg-eth0.20
echo'ONBOOT=yes' >>/etc/sysconfig/network-scripts/ifcfg-eth0.20
echo'BOOTPROTO=static' >> /etc/sysconfig/network-scripts/ifcfg-eth0.20
echo 'TYPE=ethernet'>> /etc/sysconfig/network-scripts/ifcfg-eth0.20
echo'VLAN=yes' >>/etc/sysconfig/network-scripts/ifcfg-eth0.20
echo'BRIDGE=br20' >>/etc/sysconfig/network-scripts/ifcfg-eth0.20 #(把eth0.20加入br20)
5)、配置bridge
touch /etc/sysconfig/network-scripts/ifcfg-br10
echo 'DEVICE=br10' >>/etc/sysconfig/network-scripts/ifcfg-br10
echo 'ONBOOT=yes' >>/etc/sysconfig/network-scripts/ifcfg-br10
echo 'BOOTPROTO=static' >> /etc/sysconfig/network-scripts/ifcfg-br10
echo 'TYPE=bridge' >> /etc/sysconfig/network-scripts/ifcfg-br10
touch /etc/sysconfig/network-scripts/ifcfg-br20
echo 'DEVICE=br10' >>/etc/sysconfig/network-scripts/ifcfg-br20
echo 'ONBOOT=yes' >>/etc/sysconfig/network-scripts/ifcfg-br20
echo 'BOOTPROTO=static' >> /etc/sysconfig/network-scripts/ifcfg-br20
echo 'TYPE=bridge' >>/etc/sysconfig/network-scripts/ifcfg-br20
6)、启动子接口和bridge接口
ifup eth0.10
ifup eth0.20
ifup br10
ifup br20
7)、给bridge接口配置IP
echo'IPADDR=10.10.10.2' >> /etc/sysconfig/network-scripts/ifcfg-br10
echo 'NETMASK= 255.255.255.0' >> /etc/sysconfig/network-scripts/ifcfg-br10
echo'IPADDR=10.10.20.2' >> /etc/sysconfig/network-scripts/ifcfg-br20
echo 'NETMASK= 255.255.255.0' >> /etc/sysconfig/network-scripts/ifcfg-br20
8)、添加eth0.10 eth0.20到br10、br20
brctladdif br10 eth0.10
brctladdif br20 eth0.20
9)、重启网络
service network restart
10)、设置下次启动自动加载 8021q 模块
echo 'VLAN=yes' >> /etc/sysconfig/network
echo 'modprobe 8021q' >>/etc/rc.local
服务器A和服务器B的网络配置只有bridge上的IP不同
4、IPtables服务器的配置(1)、服务器eth0口的配置1)、安装vconfig包(redhat7.0一下版本默认带vconfig包)
yum install vconfig
2)、在内核加载802.1q模块
modprobe 8021q
lsmod |grep -i8021q (查看模块是否加载)
3)、配置物理网卡
sed –i 's/ONBOOT=no/ONBOOT=yes/g' /etc/sysconfig/network-scripts/ifcfg-eth0
sed –i 's/BOOTPROTO=dhcp/BOOTPROTO=static/g'/etc/sysconfig/network-scripts/ifcfg-eth0
3)、给物理接口添加vlan并配置vlan的属性
vconfig add eth010
config set_flageth0.10 1 1
vconfig add eth0 20
config set_flag eth0.20 1 1
4)、添加eth0.10、eth0.20子接口并添加配置文件
touch/etc/sysconfig/network-scripts/ifcfg-eth0.10
echo'DEVICE=eth0.10' >>/etc/sysconfig/network-scripts/ifcfg-eth0.10
echo'ONBOOT=yes' >>/etc/sysconfig/network-scripts/ifcfg-eth0.10
echo'BOOTPROTO=static' >> /etc/sysconfig/network-scripts/ifcfg-eth0.10
echo 'TYPE=ethernet'>> /etc/sysconfig/network-scripts/ifcfg-eth0.10
echo'VLAN=yes' >>/etc/sysconfig/network-scripts/ifcfg-eth0.10
touch/etc/sysconfig/network-scripts/ifcfg-eth0.20
echo'DEVICE=eth0.20' >>/etc/sysconfig/network-scripts/ifcfg-eth0.20
echo'ONBOOT=yes' >> /etc/sysconfig/network-scripts/ifcfg-eth0.20
echo'BOOTPROTO=static' >> /etc/sysconfig/network-scripts/ifcfg-eth0.20
echo 'TYPE=ethernet'>> /etc/sysconfig/network-scripts/ifcfg-eth0.20
echo'VLAN=yes' >>/etc/sysconfig/network-scripts/ifcfg-eth0.20
5)、启动子接口
ifup eth0.10
ifup eth0.20
6)、给子接口接口配置IP
echo'IPADDR=10.10.10.254' >> /etc/sysconfig/network-scripts/ifcfg-eth0.10
echo 'NETMASK= 255.255.255.0' >> /etc/sysconfig/network-scripts/ifcfg-eth0.10
echo'IPADDR=10.10.20.254' >>/etc/sysconfig/network-scripts/ifcfg-eth0.20
echo 'NETMASK= 255.255.255.0' >>/etc/sysconfig/network-scripts/ifcfg-eth0.20
7)、重启网络
service network restart
8)、设置下次启动自动加载 8021q 模块
echo 'VLAN=yes' >> /etc/sysconfig/network
echo 'modprobe 8021q' >>/etc/rc.local
(2)、服务器eth1口的配置1)、配置物理网卡
sed –i 's/ONBOOT=no/ONBOOT=yes/g' /etc/sysconfig/network-scripts/ifcfg-eth1
sed –i 's/BOOTPROTO=dhcp/BOOTPROTO=static/g'/etc/sysconfig/network-scripts/ifcfg-eth1
2)、给物理接口添加vlan并配置vlan的属性
vconfig add eth1100
config set_flageth1.100 1 1
3)、添加eth1.100子接口并添加配置文件
touch /etc/sysconfig/network-scripts/ifcfg-eth1.100
echo 'DEVICE=eth1.100' >> /etc/sysconfig/network-scripts/ifcfg-eth1.100
echo'ONBOOT=yes' >>/etc/sysconfig/network-scripts/ifcfg-eth1.100
echo'BOOTPROTO=static' >> /etc/sysconfig/network-scripts/ifcfg-eth1.100
echo 'TYPE=ethernet'>> /etc/sysconfig/network-scripts/ifcfg-eth1.100
echo'VLAN=yes' >> /etc/sysconfig/network-scripts/ifcfg-eth1.100
4)、启动子接口
ifup eth1.100
5)、给子接口接口配置IP
echo'IPADDR=10.10.100.100' >>/etc/sysconfig/network-scripts/ifcfg-eth1.100
echo 'NETMASK= 255.255.255.0' >> /etc/sysconfig/network-scripts/ifcfg-eth1.100
echo 'GATEWAY= 10.10.100.254' >> /etc/sysconfig/network-scripts/ifcfg-eth1.100
6)、重启网络
service network restart
7)、设置下次启动自动加载 8021q 模块
echo'VLAN=yes' >> /etc/sysconfig/network
echo 'modprobe 8021q' >>/etc/rc.local
(3)、让服务器A、B内的虚拟机出网
iptables -t nat -A POSTROUTING -s10.10.10.0/24 -o eth1.100 -j MASQUERADE
iptables-t nat -A POSTROUTING -s 10.10.20.0/24 -o eth1.100 -j MASQUERADE
echo 1 > /proc/sys/net/ipv4/ip_forward
(4)、外网设备要访问vm1的80端口
iptables -t nat -A PREROUTING -p tcp -d 10.10.100.100 --dport 80-j DNAT --to-destination 10.10.10.11:80
把外网设备访问10.10.100.100的80端口映射到vm1设备的80端口
原文:
http://www.iyunv.com/thread-51063-1-1.html |