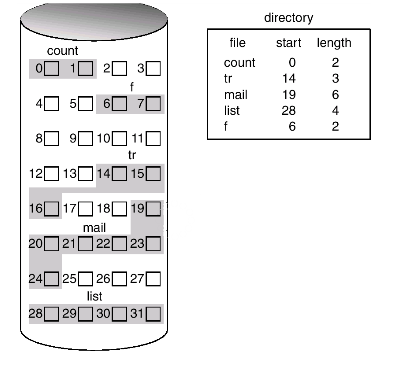
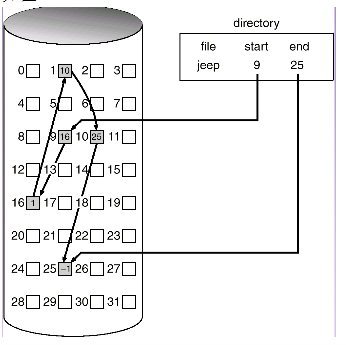
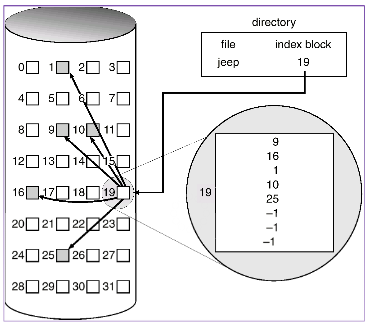
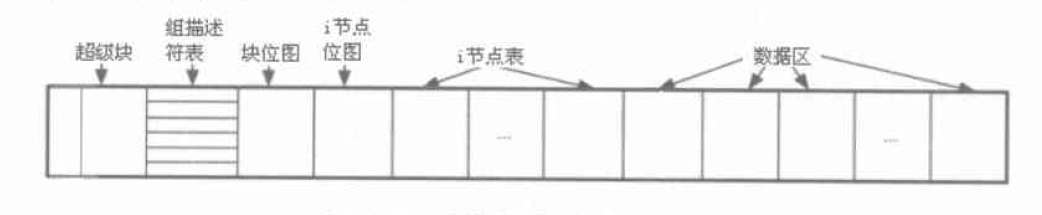
mds
用于元数据服务器的配置和管理,需额外指定子命令。
子命令 add_data_pool 用于增加数据存储池。
用法:
ceph mds add_data_pool <pool>
子命令 cluster_down 关闭 mds 集群。
用法:
子命令 cluster_up 启动 mds 集群。
用法:
子命令 compat 管理兼容功能,需额外指定子命令。
子命令 rm_compat 可删除兼容功能。
用法:
ceph mds compat rm_compat <int[0-]>
子命令 rm_incompat 可删除不兼容的功能。
用法:
ceph mds compat rm_incompat <int[0-]>
子命令 show 可查看 mds 的兼容性选项。
用法:
子命令 deactivate 可停止 mds 。
用法:
ceph mds deactivate <who>
子命令 dump 用于转储信息, epoch 号为可选。
用法:
ceph mds dump {<int[0-]>}
子命令 fail 强制把 mds 状态设置为失效。
用法:
子命令 getmap 获取 MDS 图, epoch 号可选。
用法:
ceph mds getmap {<int[0-]>}
子命令 newfs 可用 <metadata> 和 <data> 存储池新建文件系统。
用法:
ceph mds newfs <int[0-]> <int[0-]> {--yes-i-really-mean-it}
子命令 remove_data_pool 用于删除数据存储池。
用法:
ceph mds remove_data_pool <pool>
子命令 rm 用于删除不活跃的 mds 。
用法:
ceph mds rm <int[0-]> <name> (type.id)>
子命令 rmfailed 用于删除失效的 mds 。
用法:
ceph mds rmfailed <int[0-]>
子命令 set 用于设置参数,把 <var> 的值设置为 <val> 。
用法:
ceph mds set max_mds|max_file_size|allow_new_snaps|inline_data <va> {<confirm>}
子命令 set_max_mds 用于设置 MDS 的最大索引号。
用法:
ceph mds set_max_mds <int[0-]>
子命令 set_state 把 mds 状态从 <gid> 改为 <numeric-state> 。
用法:
ceph mds set_state <int[0-]> <int[0-20]>
子命令 setmap 设置 mds 图,必须提供正确的 epoch 号。
用法:
ceph mds setmap <int[0-]>
子命令 stat 显示 MDS 状态。
用法:
子命令 stop 停止指定 mds 。
用法:
子命令 tell 用于向某个 mds 发送命令。
用法:
ceph mds tell <who> <args> [<args>...]
osd
用于配置和管理 OSD ,需额外指定子命令。
子命令 blacklist 用于管理客户端黑名单,需额外加子命令。
子命令 add 用于把 <addr> 加入黑名单(可指定时间,从现在起 <expire> 秒)。
用法:
ceph osd blacklist add <EntityAddr> {<float[0.0-]>}
子命令 ls 列出进黑名单的客户端。
用法:
子命令 rm 从黑名单里删除 <addr> 。
用法:
ceph osd blacklist rm <EntityAddr>
子命令 blocked-by 用于罗列哪些 OSD 在阻塞互联。
用法:
子命令 create 用于新建 OSD , UUID 和 ID 是可选的。
用法:
ceph osd create {<uuid>} {<id>}
子命令 crush 用于 CRUSH 管理,需额外指定子命令。
子命令 add 可用于新增或更新 <name> 的 crushmap 位置及权重,权重改为 <weight> 、位置为 <args> 。
用法:
ceph osd crush add <osdname (id|osd.id)> <float[0.0-]> <args> [<args>...]
子命令 add-bucket 可新增没有父级(可能是 root )、类型为 <type> 、名为 <name> 的 crush 桶。
用法:
ceph osd crush add-bucket <name> <type>
子命令 create-or-move 用于创建名为 <name> 、权重为 <weight> 的条目并放置到 <args> ,若已存在则移动到指定位置 <args> 。
用法:
ceph osd crush create-or-move <osdname (id|osd.id)> <float[0.0-]>
<args> [<args>...]
子命令 dump 用于转储 crush 图。
用法:
子命令 get-tunable 用于获取 CRUSH 可调值 straw_calc_version 。
用法:
ceph osd crush get-tunable straw_calc_version
子命令 link 用于把已存在条目 <name> 链接到 <args> 位置下。
用法:
ceph osd crush link <name> <args> [<args>...]
子命令 move 可把已有条目 <name> 移动到 <args> 位置。
用法:
ceph osd crush move <name> <args> [<args>...]
子命令 remove 把 crush 图中(任意位置,或 <ancestor> 之下的)的 <name> 删掉。
用法:
ceph osd crush remove <name> {<ancestor>}
子命令 rename-bucket 可把桶 <srcname> 重命名为 <dstname> 。
用法:
ceph osd crush rename-bucket <srcname> <dstname>
子命令 reweight 把 crush 图中 <name> 的权重改为 <weight> 。
用法:
ceph osd crush reweight <name> <float[0.0-]>
子命令 reweight-all 重新计算树的权重,以确保权重之和没算错。
用法:
ceph osd crush reweight-all
子命令 reweight-subtree 用于把 CRUSH 图内 <name> 之下的所有叶子条目的权重改为 <weight> 。
用法:
ceph osd crush reweight-subtree <name> <weight>
子命令 rm 把 crush 图中(任意位置,或 <ancestor> 之下的)的 <name> 删掉。
用法:
ceph osd crush rm <name> {<ancestor>}
子命令 rule 用于创建 crush 规则,需额外加子命令。
子命令 create-erasure 可为纠删码存储池(用 <profile> 创建的))创建名为 <name> 的 crush 规则,默认为 default 。
用法:
ceph osd crush rule create-erasure <name> {<profile>}
子命令 create-simple 创建从 <root> 开始、名为 <name> 的 crush 规则,副本将跨 <type> 类型进行散布,选择模式为 <firstn|indep> (默认 firstn ,indep 更适合纠删码存储池)。
用法:
ceph osd crush rule create-simple <name> <root> <type> {firstn|indep}
子命令 dump 转储名为 <name> 的 crush 规则,默认全部转储。
用法:
ceph osd crush rule dump {<name>}
子命令 list 罗列 crush 规则。
用法:
子命令 ls 罗列 crush 规则。
用法:
子命令 rm 删除 crush 规则 <name> 。
用法:
ceph osd crush rule rm <name>
子命令 set 单独使用,把输入文件设置为 crush 图。
用法:
子命令 set 为 osdname 或 osd.id 更新 crush 图的位置和权重信息,把名为 <name> 的 OSD 权重设置为 <weight> 、位置设置为 <args> 。
用法:
ceph osd crush set <osdname (id|osd.id)> <float[0.0-]> <args> [<args>...]
子命令 set-tunable 把可调值 <tunable> 设置为 <value> 。唯一能设置的可调值是 straw_calc_version 。
用法:
ceph osd crush set-tunable straw_calc_version <value>
子命令 show-tunables 显示当前的 crush 可调值。
用法:
ceph osd crush show-tunables
子命令 tree 用树状视图显示各 crush 桶、及各条目。
用法:
子命令 tunables 设置 <profile> 中的 crush 可调值。
用法:
ceph osd crush tunables legacy|argonaut|bobtail|firefly|hammer|optimal|default
子命令 unlink 从 crush 图中解链接出 <name> (任意位置,或 <ancestor> 之下的)。
用法:
ceph osd crush unlink <name> {<ancestor>}
子命令 df 用于显示 OSD 利用率。
用法:
子命令 deep-scrub 可启动指定 OSD 的深度洗刷。
用法:
ceph osd deep-scrub <who>
子命令 down 把 osd(s) <id> [<id>...] 状态设置为 down 。
用法:
ceph osd down <ids> [<ids>...]
子命令 dump 打印 OSD 图汇总。
用法:
ceph osd dump {<int[0-]>}
子命令 erasure-code-profile 用于管理纠删码配置,需额外加子命令。
子命令 get 读取纠删码配置 <name> 。
用法:
ceph osd erasure-code-profile get <name>
子命令 ls 罗列所有纠删码配置。
用法:
ceph osd erasure-code-profile ls
子命令 rm 删除纠删码配置 <name> 。
用法:
ceph osd erasure-code-profile rm <name>
子命令 set 用给定的参数 [<key[=value]> ...] 创建纠删码配置 <name> 。末尾加 –force 可覆盖已有配置(慎用)。
用法:
ceph osd erasure-code-profile set <name> {<profile> [<profile>...]}
子命令 find 从 CRUSH 图中找到 osd <id> 并显示其位置。
用法:
子命令 getcrushmap 获取 CRUSH 图。
用法:
ceph osd getcrushmap {<int[0-]>}
子命令 getmap 获取 OSD 图。
用法:
ceph osd getmap {<int[0-]>}
子命令 getmaxosd 显示最大 OSD 惟一标识符。
用法:
子命令 in 把给出的 OSD <id> [<id>...] 标识为 in 状态。
用法:
ceph osd in <ids> [<ids>...]
子命令 lost 把 OSD 标识为永久丢失。如果没有多个副本,此命令会导致数据丢失,慎用。
用法:
ceph osd lost <int[0-]> {--yes-i-really-mean-it}
子命令 ls 显示所有 OSD 的惟一标识符。
用法:
子命令 lspools 罗列存储池。
用法:
子命令 map 在 <pool> 存储池中找 <object> 对象所在的归置组号码。
用法:
ceph osd map <poolname> <objectname>
子命令 metadata 为 osd <id> 取出元数据。
用法:
ceph osd metadata {int[0-]} (default all)
子命令 out 把指定 OSD <id> [<id>...] 的状态设置为 out 。
用法:
ceph osd out <ids> [<ids>...]
子命令 pause 暂停 osd 。
用法:
子命令 perf 打印 OSD 的性能统计摘要。
用法:
子命令 pg-temp 设置 pg_temp 映射 pgid:[<id> [<id>...]] ,适用于开发者。
用法:
ceph osd pg-temp <pgid> {<id> [<id>...]}
子命令 pool 用于管理数据存储池,需额外加子命令。
子命令 create 创建存储池。
用法:
ceph osd pool create <poolname> <int[0-]> {<int[0-]>} {replicated|erasure}
{<erasure_code_profile>} {<ruleset>} {<int>}
子命令 delete 删除存储池。
用法:
ceph osd pool delete <poolname> {<poolname>} {--yes-i-really-really-mean-it}
子命令 get 获取存储池参数 <var> 。
用法:
ceph osd pool get <poolname> size|min_size|crash_replay_interval|pg_num|
pgp_num|crush_ruleset|auid|write_fadvise_dontneed
以下命令只适用于分层存储池:
ceph osd pool get <poolname> hit_set_type|hit_set_period|hit_set_count|hit_set_fpp|
target_max_objects|target_max_bytes|cache_target_dirty_ratio|cache_target_dirty_high_ratio|
cache_target_full_ratio|cache_min_flush_age|cache_min_evict_age|
min_read_recency_for_promote|hit_set_grade_decay_rate|hit_set_search_last_n
以下命令只适用于纠删码存储池:
ceph osd pool get <poolname> erasure_code_profile
子命令 get-quota 获取存储池的对象或字节数限额。
用法:
ceph osd pool get-quota <poolname>
子命令 ls 用于罗列存储池。
用法:
ceph osd pool ls {detail}
子命令 mksnap 拍下存储池 <pool> 的快照 <snap> 。
用法:
ceph osd pool mksnap <poolname> <snap>
子命令 rename 把存储池 <srcpool> 重命名为 <destpool> 。
用法:
ceph osd pool rename <poolname> <poolname>
子命令 rmsnap 删除存储池 <pool> 的快照 <snap> 。
用法:
ceph osd pool rmsnap <poolname> <snap>
子命令 set 把存储池参数 <var> 的值设置为 <val> 。
用法:
ceph osd pool set <poolname> size|min_size|crash_replay_interval|pg_num|
pgp_num|crush_ruleset|hashpspool|nodelete|nopgchange|nosizechange|
hit_set_type|hit_set_period|hit_set_count|hit_set_fpp|debug_fake_ec_pool|
target_max_bytes|target_max_objects|cache_target_dirty_ratio|
cache_target_dirty_high_ratio|
cache_target_full_ratio|cache_min_flush_age|cache_min_evict_age|auid|
min_read_recency_for_promote|write_fadvise_dontneed|hit_set_grade_decay_rate|
hit_set_search_last_n
<val> {--yes-i-really-mean-it}
子命令 set-quota 设置存储池的对象或字节数限额。
用法:
ceph osd pool set-quota <poolname> max_objects|max_bytes <val>
子命令 stats 获取所有或指定存储池的统计信息。
用法:
ceph osd pool stats {<name>}
子命令 primary-affinity 设置主 OSD 亲和性,有效值范围 0.0 <= <weight> <= 1.0
用法:
ceph osd primary-affinity <osdname (id|osd.id)> <float[0.0-1.0]>
子命令 primary-temp 设置 primary_temp 映射 pgid:<id>|-1 ,适用于开发者。
用法:
ceph osd primary-temp <pgid> <id>
子命令 repair 让指定 OSD 开始修复。
用法:
子命令 reweight 把 OSD 权重改为 0.0 < <weight> < 1.0 之间的值。
用法:
osd reweight <int[0-]> <float[0.0-1.0]>
子命令 reweight-by-pg 按归置组分布情况调整 OSD 的权重(考虑的过载百分比,默认 120 )。
用法:
ceph osd reweight-by-pg {<int[100-]>} {<poolname> [<poolname...]}
子命令 reweight-by-utilization 按利用率调整 OSD 的权重,还需考虑负载比率,默认 120 。
用法:
ceph osd reweight-by-utilization {<int[100-]>}
子命令 rm 删除集群中的 OSD ,其编号为 <id> [<id>...] 。
用法:
ceph osd rm <ids> [<ids>...]
子命令 scrub 让指定 OSD 开始洗刷。
用法:
子命令 set 设置关键字 <key> 。
用法:
ceph osd set full|pause|noup|nodown|noout|noin|nobackfill|
norebalance|norecover|noscrub|nodeep-scrub|notieragent
子命令 setcrushmap 把输入文件设置为 CRUSH 图。
用法:
子命令 setmaxosd 设置最大 OSD 数值。
用法:
ceph osd setmaxosd <int[0-]>
子命令 stat 打印 OSD 图摘要。
用法:
子命令 thrash 把 OSD 元版本回滚到 <num_epochs> 。
用法:
ceph osd thrash <int[0-]>
子命令 tier 用于管理(存储池)分级,需额外加子命令。
子命令 add 把 <tierpool> (第二个)加到基础存储池 <pool> (第一个)之前。
用法:
ceph osd tier add <poolname> <poolname> {--force-nonempty}
子命令 add-cache 把尺寸为 <size> 的缓存存储池 <tierpool> (第二个)加到现有存储池 <pool> (第一个)之前。
用法:
ceph osd tier add-cache <poolname> <poolname> <int[0-]>
子命令 cache-mode 设置缓存存储池 <pool> 的缓存模式。
用法:
ceph osd tier cache-mode <poolname> none|writeback|forward|readonly|
readforward|readproxy
子命令 remove 删掉基础存储池 <pool> (第一个)的马甲存储池 <tierpool> (第二个)。
用法:
ceph osd tier remove <poolname> <poolname>
子命令 remove-overlay 删除基础存储池 <pool> 的马甲存储池。
用法:
ceph osd tier remove-overlay <poolname>
子命令 set-overlay 把 <overlaypool> 设置为基础存储池 <pool> 的马甲存储池。
用法:
ceph osd tier set-overlay <poolname> <poolname>
子命令 tree 打印 OSD 树。
用法:
ceph osd tree {<int[0-]>}
子命令 unpause 取消 osd 暂停。
用法:
子命令 unset 取消设置的关键字 <key> 。
用法:
ceph osd unset full|pause|noup|nodown|noout|noin|nobackfill|
norebalance|norecover|noscrub|nodeep-scrub|notieragent
pg
用于管理 OSD 内的归置组,需额外加子命令。
子命令 debug 可显示归置组的调试信息。
用法:
ceph pg debug unfound_objects_exist|degraded_pgs_exist
子命令 deep-scrub 开始深度洗刷归置组 <pgid> 。
用法:
ceph pg deep-scrub <pgid>
子命令 dump 可显示归置组图的人类可读版本(显示为纯文本时只有 ‘all’ 合法)。
用法:
ceph pg dump {all|summary|sum|delta|pools|osds|pgs|pgs_brief} [{all|summary|sum|delta|pools|osds|pgs|pgs_brief...]}
子命令 dump_json 只以 json 格式显示归置组图的人类可读版本。
用法:
ceph pg dump_json {all|summary|sum|delta|pools|osds|pgs|pgs_brief} [{all|summary|sum|delta|pools|osds|pgs|pgs_brief...]}
子命令 dump_pools_json 只以 json 格式显示归置组存储池信息[译者:存疑]。
用法:
子命令 dump_stuck 显示卡顿归置组的信息。
用法:
ceph pg dump_stuck {inactive|unclean|stale|undersized|degraded [inactive|unclean|stale|undersized|degraded...]}
{<int>}
子命令 force_create_pg 强制创建归置组 <pgid> 。
用法:
ceph pg force_create_pg <pgid>
子命令 getmap 获取二进制归置组图,保存到 -o/stdout 。
用法:
子命令 ls 可根据指定存储池、 OSD 、状态罗列对应的归置组。
用法:
ceph pg ls {<int>} {active|clean|down|replay|splitting|
scrubbing|scrubq|degraded|inconsistent|peering|repair|
recovery|backfill_wait|incomplete|stale| remapped|
deep_scrub|backfill|backfill_toofull|recovery_wait|
undersized [active|clean|down|replay|splitting|
scrubbing|scrubq|degraded|inconsistent|peering|repair|
recovery|backfill_wait|incomplete|stale|remapped|
deep_scrub|backfill|backfill_toofull|recovery_wait|
undersized...]}
子命令 ls-by-osd 用于罗列指定 OSD 上的归置组。
用法:
ceph pg ls-by-osd <osdname (id|osd.id)> {<int>}
{active|clean|down|replay|splitting|
scrubbing|scrubq|degraded|inconsistent|peering|repair|
recovery|backfill_wait|incomplete|stale| remapped|
deep_scrub|backfill|backfill_toofull|recovery_wait|
undersized [active|clean|down|replay|splitting|
scrubbing|scrubq|degraded|inconsistent|peering|repair|
recovery|backfill_wait|incomplete|stale|remapped|
deep_scrub|backfill|backfill_toofull|recovery_wait|
undersized...]}
子命令 ls-by-pool 用于罗列存储池 [poolname | poolid] 内的归置组。
用法:
ceph pg ls-by-pool <poolstr> {<int>} {active|
clean|down|replay|splitting|
scrubbing|scrubq|degraded|inconsistent|peering|repair|
recovery|backfill_wait|incomplete|stale| remapped|
deep_scrub|backfill|backfill_toofull|recovery_wait|
undersized [active|clean|down|replay|splitting|
scrubbing|scrubq|degraded|inconsistent|peering|repair|
recovery|backfill_wait|incomplete|stale|remapped|
deep_scrub|backfill|backfill_toofull|recovery_wait|
undersized...]}
子命令 ls-by-primary 可罗列主 OSD 为 [osd] 的归置组。
用法:
ceph pg ls-by-primary <osdname (id|osd.id)> {<int>}
{active|clean|down|replay|splitting|
scrubbing|scrubq|degraded|inconsistent|peering|repair|
recovery|backfill_wait|incomplete|stale| remapped|
deep_scrub|backfill|backfill_toofull|recovery_wait|
undersized [active|clean|down|replay|splitting|
scrubbing|scrubq|degraded|inconsistent|peering|repair|
recovery|backfill_wait|incomplete|stale|remapped|
deep_scrub|backfill|backfill_toofull|recovery_wait|
undersized...]}
子命令 map 显示归置组到 OSD 的映射关系。
用法:
子命令 repair 开始修复归置组 <pgid> 。
用法:
子命令 scrub 开始洗刷归置组 <pgid> 。
用法:
子命令 set_full_ratio 设置认为归置组占满的比率。
用法:
ceph pg set_full_ratio <float[0.0-1.0]>
子命令 set_nearfull_ratio 设置认为归置组将要占满的比率。
用法:
ceph pg set_nearfull_ratio <float[0.0-1.0]>
子命令 stat 显示归置组状态。
用法: