
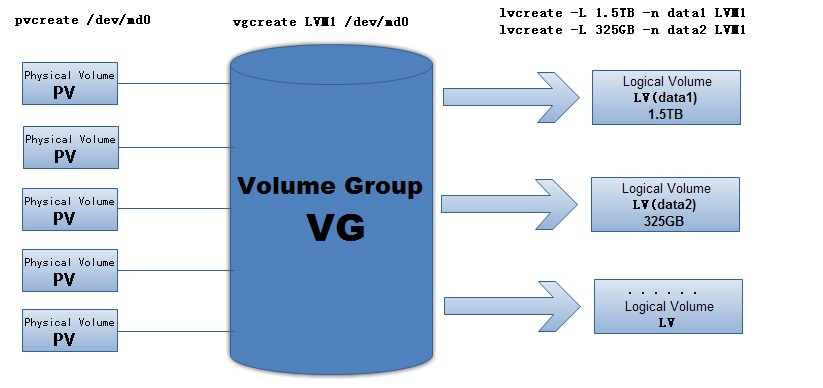
project
|-- androids
| -- tags
| -- trunk
| -- branches
|-- design
|-- documents
|-- references
|-- webs
| -- tags
| -- trunk
| -- branches
project
|-- androids
| -- tags
| -- trunk
| -- branches
|-- design
|-- documents
|-- references
|-- webs
| -- tags
| -- trunk
| -- branches
可用于程序员智能感知或生成类MSDN文档。
列表一:
| 标签语法 | 说明 | 语法 | 参数 |
|
<summary> |
<summary> 标记应当用于描述类型或类型成员。使用 <remarks> 添加针对某个类型说明的补充信息。
<summary> 标记的文本是唯一有关 IntelliSense 中的类型的信息源,它也显示在 对象浏览器 中。 |
<summary> Description </summary> |
description:对象的摘要。 |
|
<remarks> |
使用 <remarks>标记添加有关类型的信息,以此补充用 <summary> 指定的信息。此信息显示在对象浏览器中。 |
<remarks> Description </remarks> |
description:成员的说明。 |
|
<param> |
<param> 标记应当用于方法声明的注释中,以描述方法的一个参数。
有关 <param> 标记的文本将显示在 IntelliSense、对象浏览器和代码注释 Web 报表中。 |
<paramname='name'> description </param> |
name:方法参数名。将此名称用双引号括起来 (" ")。
description:参数说明。 |
|
<returns> |
<returns> 标记应当用于方法声明的注释,以描述返回值。 |
<returns> Description </returns> |
description:返回值的说明。 |
|
<value> |
<value> 标记使您得以描述属性所代表的值。请注意,当在 Visual Studio .NET 开发环境中通过代码向导添加属性时,它将会为新属性添加 <summary> 标记。然后,应该手动添加 <value> 标记以描述该属性所表示的值。 |
<value> property-description </value> |
property-description:属性的说明 |
|
<example> |
使用 <example> 标记可以指定使用方法或其他库成员的示例。这通常涉及使用 <code> 标记。 |
<example> Description </example> |
description: 代码示例的说明。 |
|
<c> |
<c> 标记为您提供了一种将说明中的文本标记为代码的方法。使用 <code> 将多行指示为代码。 |
<c> Text </c> |
text :希望将其指示为代码的文本。 |
|
<code> |
使用 <code> 标记将多行指示为代码。使用<c>指示应将说明中的文本标记为代码。 |
<code> Content </code> |
content:希望将其标记为代码的文本。 |
|
<exception> |
<exception> 标记使您可以指定哪些异常可被引发。此标记可用在方法、属性、事件和索引器的定义中。 |
<exception cref="member"> Description </exception> |
cref: 对可从当前编译环境中获取的异常的引用。编译器检查到给定异常存在后,将 member 转换为输出 XML 中的规范化元素名。必须将 member 括在双引号 (" ") 中。 有关如何创建对泛型类型的 cref 引用的更多信息,请参见 <see> description:异常的说明。 |
|
<see> <seealso> |
<see> 标记使您得以从文本内指定链接。使用 <seealso> 指示文本应该放在“另请参见”节中。 |
<seecref="member"/> |
cref:
对可以通过当前编译环境进行调用的成员或字段的引用。编译器检查给定的代码元素是否存在,并将 member 传递给输出 XML 中的元素名称。应将 member 放在双引号 (" ") 中。 |
|
<para> |
<para> 标记用于诸如<summary>,<remarks> 或 <returns> 等标记内,使您得以将结构添加到文本中。 |
<para>content</para> |
content:段落文本。 |
|
<code>* |
提供了一种插入代码的方法。 |
<code src="src" language="lan" encoding="c"/> |
src:代码文件的位置
language:代码的计算机语言 encoding:文件的编码 |
|
<img>* |
用以在文档中插入图片 |
<imgsrc="src"/> |
src:图片的位置,相对于注释所在的XML文件 |
|
<file>* |
用以在文档中插入文件,在页面中表现为下载链接 |
<filesrc="src"/> |
src:文件的位置,相对于注释所在的XML文件 |
|
<localize>* |
提供一种注释本地化的方法,名称与当前线程语言不同的子节点将被忽略 |
<localize> <zh-CHS>中文</zh-CHS> <en>English</en> ... </localize> |
...
a.下载包
打开 https://dev.mysql.com/downloads/repo/yum/ 选择对应版本
点击下一download 后,复制 No thanks, just start my download. 上的连接
下载:
wget https://dev.mysql.com/get/mysql57-community-release-el6-9.noarch.rpm
b.安装用来配置mysql的yum源的rpm包
rpm -Uvh mysql57-community-release-el6-9.noarch.rpm
或
yum localinstall -y mysql57-community-release-el6-9.noarch.rpm
安装成功后在/etc/yum.repos.d/
2.安装mysql
yum install mysql-community-server
3.开启mysql服务
service mysqld start
4.默认密码
启动后创建的超级用户'root'@'localhost' 密码被存储在/var/log/mysqld.log
命令查看密码
grep 'password' /var/log/mysqld.log
使用mysql生成的'root'@'localhost'用户和密码登录数据库,并修改默认密码
shell> mysql -uroot -p
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'newpassword';
--
Linux 根分区扩容
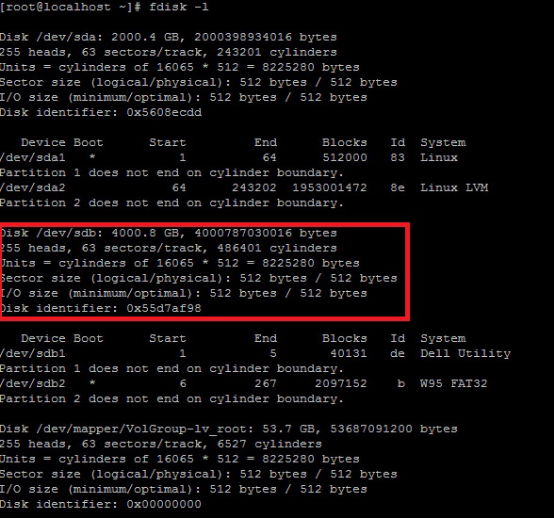
1.fdisk –l (红线部分为新添加的硬盘)
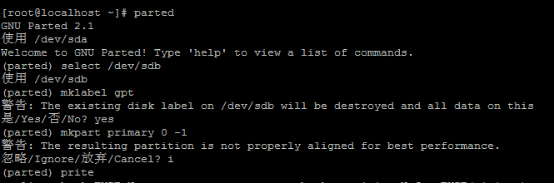
2.磁盘格式化
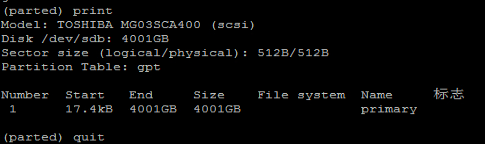
3. mkfs.ext3 -T largefile /dev/sde1(格式化上面的分区)
4. vgdisplay 查看当前卷组情况(红色内容表明没有可用的扩展空间)
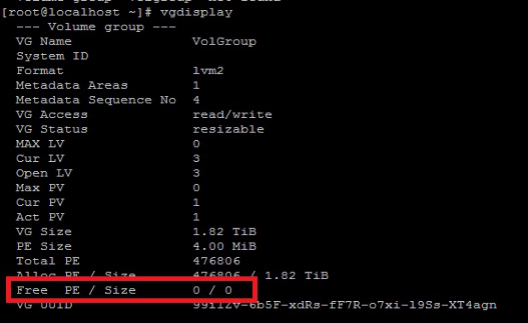
5. pvcreate /dev/sde1 创建pv
6. vgextend VolGroup /dev/sde1 创建vg
![]()
7. lvextend -L +3000G /dev/mapper/VolGroup-lv_root
# lvextend -l +100%FREE /dev/centos/root
lvextend -l +100%FREE /dev/mapper/VolGroup-lv_root

8. vgdisplay (红色为添加的空间)
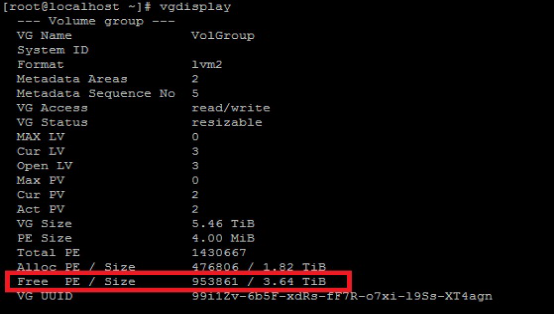
9.resize2fs /dev/mapper/VolGroup-lv_root 文件系统重定义大小,根据机器配置不同大约需要1小时左右
如果为 xfs 格式,则使用:xfs_growfs
# xfs_growfs /dev/mapper/centos-root
xfs_growfs /dev/mapper/VolGroup-lv_root

10.扩容前后对比
扩容前:

扩容后:

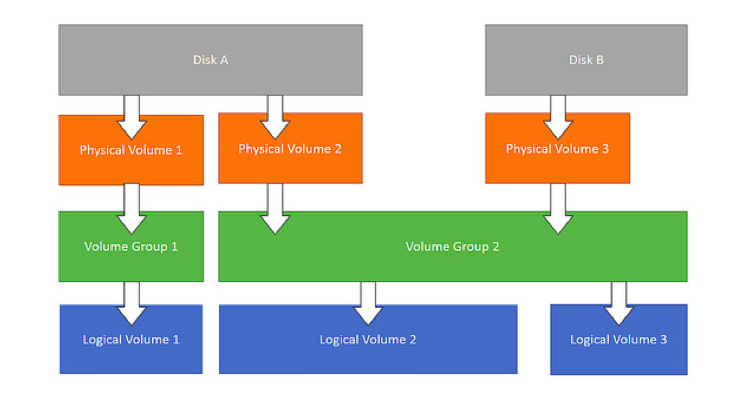
扩容 LVM 分区组
1,分区卷
fdisk /dev/sda 操作 /dev/sda 的分区表
p 查看已分区数量(已有两个 /dev/sda1 /dev/sda2)
n 新增加一个分区
p 分区类型我们选择为主分区
3 分区号选3(因为1,2已经用过了,见上)
回车 默认(起始扇区)|或sda2结束区
回车 默认(结束扇区)
t 修改分区类型
3 选分区3
8e 修改为LVM(8e就是LVM)
w 写分区表
q 完成,退出fdisk命令
根据系统提示,重启
2,开机后,格式化:
mkfs.ext4 /dev/sda3
3,创建物理卷
pvcreate /dev/sda3
4,将物理卷扩展到卷组
vgextend VolGroup /dev/sdb1
VolGroup 名称通过 vgdisplay 查看
5,将卷组中的空闲空间扩展到根分区逻辑卷
lvextend -l +100%FREE /dev/VolGroup/lv_root
不使用100%时可以使用 +具体值, 值为vgdisplay中Free PE
6,刷新根分区
centos6
resize2fs /dev/VolGroup/lv_root
centos7
xfs_growfs /dev/centos/root
| 语言代码 | 国家/ 地区 |
| "" (空字符串) | 无变化的文化 |
| af | 公用荷兰语 |
| af-ZA | 公用荷兰语 - 南非 |
| sq | 阿尔巴尼亚 |
| sq-AL | 阿尔巴尼亚 -阿尔巴尼亚 |
| ar | 阿拉伯语 |
| ar-DZ | 阿拉伯语 -阿尔及利亚 |
| ar-BH | 阿拉伯语 -巴林 |
| ar-EG | 阿拉伯语 -埃及 |
| ar-IQ | 阿拉伯语 -伊拉克 |
| ar-JO | 阿拉伯语 -约旦 |
| ar-KW | 阿拉伯语 -科威特 |
| ar-LB | 阿拉伯语 -黎巴嫩 |
| ar-LY | 阿拉伯语 -利比亚 |
| ar-MA | 阿拉伯语 -摩洛哥 |
| ar-OM | 阿拉伯语 -阿曼 |
| ar-QA | 阿拉伯语 -卡塔尔 |
| ar-SA | 阿拉伯语 - 沙特阿拉伯 |
| ar-SY | 阿拉伯语 -叙利亚共和国 |
| ar-TN | 阿拉伯语 -北非的共和国 |
| ar-AE | 阿拉伯语 - 阿拉伯联合酋长国 |
| ar-YE | 阿拉伯语 -也门 |
| hy | 亚美尼亚 |
| hy-AM | 亚美尼亚的 -亚美尼亚 |
| az | Azeri |
| az-AZ-Cyrl | Azeri-(西里尔字母的) 阿塞拜疆 |
| az-AZ-Latn | Azeri(拉丁文)- 阿塞拜疆 |
| eu | 巴斯克 |
| eu-ES | 巴斯克 -巴斯克 |
| be | Belarusian |
| be-BY | Belarusian-白俄罗斯 |
| bg | 保加利亚 |
| bg-BG | 保加利亚 -保加利亚 |
| ca | 嘉泰罗尼亚 |
| ca-ES | 嘉泰罗尼亚 -嘉泰罗尼亚 |
| zh-HK | 华 - 香港的 SAR |
| zh-MO | 华 - 澳门的 SAR |
| zh-CN | 华 -中国 |
| zh-CHS | 华 (单一化) |
| zh-SG | 华 -新加坡 |
| zh-TW | 华 -台湾 |
| zh-CHT | 华 (传统的) |
| hr | 克罗埃西亚 |
| hr-HR | 克罗埃西亚 -克罗埃西亚 |
| cs | 捷克 |
| cs-CZ | 捷克 - 捷克 |
| da | 丹麦文 |
| da-DK | 丹麦文 -丹麦 |
| div | Dhivehi |
| div-MV | Dhivehi-马尔代夫 |
| nl | 荷兰 |
| nl-BE | 荷兰 -比利时 |
| nl-NL | 荷兰 - 荷兰 |
| en | 英国 |
| en-AU | 英国 -澳洲 |
| en-BZ | 英国 -伯利兹 |
| en-CA | 英国 -加拿大 |
| en-CB | 英国 -加勒比海 |
| en-IE | 英国 -爱尔兰 |
| en-JM | 英国 -牙买加 |
| en-NZ | 英国 - 新西兰 |
| en-PH | 英国 -菲律宾共和国 |
| en-ZA | 英国 - 南非 |
| en-TT | 英国 - 千里达托贝哥共和国 |
| en-GB | 英国 - 英国 |
| en-US | 英国 - 美国 |
| en-ZW | 英国 -津巴布韦 |
| et | 爱沙尼亚 |
| et-EE | 爱沙尼亚的 -爱沙尼亚 |
| fo | Faroese |
| fo-FO | Faroese- 法罗群岛 |
| fa | 波斯语 |
| fa-IR | 波斯语 -伊朗王国 |
| fi | 芬兰语 |
| fi-FI | 芬兰语 -芬兰 |
| fr | 法国 |
| fr-BE | 法国 -比利时 |
| fr-CA | 法国 -加拿大 |
| fr-FR | 法国 -法国 |
| fr-LU | 法国 -卢森堡 |
| fr-MC | 法国 -摩纳哥 |
| fr-CH | 法国 -瑞士 |
| gl | 加利西亚 |
| gl-ES | 加利西亚 -加利西亚 |
| ka | 格鲁吉亚州 |
| ka-GE | 格鲁吉亚州 -格鲁吉亚州 |
| de | 德国 |
| de-AT | 德国 -奥地利 |
| de-DE | 德国 -德国 |
| de-LI | 德国 -列支敦士登 |
| de-LU | 德国 -卢森堡 |
| de-CH | 德国 -瑞士 |
| el | 希腊 |
| el-GR | 希腊 -希腊 |
| gu | Gujarati |
| gu-IN | Gujarati-印度 |
| he | 希伯来 |
| he-IL | 希伯来 -以色列 |
| hi | 北印度语 |
| hi-IN | 北印度的 -印度 |
| hu | 匈牙利 |
| hu-HU | 匈牙利的 -匈牙利 |
| is | 冰岛语 |
| is-IS | 冰岛的 -冰岛 |
| id | 印尼 |
| id-ID | 印尼 -印尼 |
| it | 意大利 |
| it-IT | 意大利 -意大利 |
| it-CH | 意大利 -瑞士 |
| ja | 日本 |
| ja-JP | 日本 -日本 |
| kn | 卡纳达语 |
| kn-IN | 卡纳达语 -印度 |
| kk | Kazakh |
| kk-KZ | Kazakh-哈萨克 |
| kok | Konkani |
| kok-IN | Konkani-印度 |
| ko | 韩国 |
| ko-KR | 韩国 -韩国 |
| ky | Kyrgyz |
| ky-KZ | Kyrgyz-哈萨克 |
| lv | 拉脱维亚 |
| lv-LV | 拉脱维亚的 -拉脱维亚 |
| lt | 立陶宛 |
| lt-LT | 立陶宛 -立陶宛 |
| mk | 马其顿 |
| mk-MK | 马其顿 -FYROM |
| ms | 马来 |
| ms-BN | 马来 -汶莱 |
| ms-MY | 马来 -马来西亚 |
| mr | 马拉地语 |
| mr-IN | 马拉地语 -印度 |
| mn | 蒙古 |
| mn-MN | 蒙古 -蒙古 |
| no | 挪威 |
| nb-NO | 挪威 (Bokm?l) - 挪威 |
| nn-NO | 挪威 (Nynorsk)- 挪威 |
| pl | 波兰 |
| pl-PL | 波兰 -波兰 |
| pt | 葡萄牙 |
| pt-BR | 葡萄牙 -巴西 |
| pt-PT | 葡萄牙 -葡萄牙 |
| pa | Punjab 语 |
| pa-IN | Punjab 语 -印度 |
| ro | 罗马尼亚语 |
| ro-RO | 罗马尼亚语 -罗马尼亚 |
| ru | 俄国 |
| ru-RU | 俄国 -俄国 |
| sa | 梵文 |
| sa-IN | 梵文 -印度 |
| sr-SP-Cyrl | 塞尔维亚 -(西里尔字母的) 塞尔维亚共和国 |
| sr-SP-Latn | 塞尔维亚 (拉丁文)- 塞尔维亚共和国 |
| sk | 斯洛伐克 |
| sk-SK | 斯洛伐克 -斯洛伐克 |
| sl | 斯洛文尼亚 |
| sl-SI | 斯洛文尼亚 -斯洛文尼亚 |
| es | 西班牙 |
| es-AR | 西班牙 -阿根廷 |
| es-BO | 西班牙 -玻利维亚 |
| es-CL | 西班牙 -智利 |
| es-CO | 西班牙 -哥伦比亚 |
| es-CR | 西班牙 - 哥斯达黎加 |
| es-DO | 西班牙 - 多米尼加共和国 |
| es-EC | 西班牙 -厄瓜多尔 |
| es-SV | 西班牙 - 萨尔瓦多 |
| es-GT | 西班牙 -危地马拉 |
| es-HN | 西班牙 -洪都拉斯 |
| es-MX | 西班牙 -墨西哥 |
| es-NI | 西班牙 -尼加拉瓜 |
| es-PA | 西班牙 -巴拿马 |
| es-PY | 西班牙 -巴拉圭 |
| es-PE | 西班牙 -秘鲁 |
| es-PR | 西班牙 - 波多黎各 |
| es-ES | 西班牙 -西班牙 |
| es-UY | 西班牙 -乌拉圭 |
| es-VE | 西班牙 -委内瑞拉 |
| sw | Swahili |
| sw-KE | Swahili-肯尼亚 |
| sv | 瑞典 |
| sv-FI | 瑞典 -芬兰 |
| sv-SE | 瑞典 -瑞典 |
| syr | Syriac |
| syr-SY | Syriac-叙利亚共和国 |
| ta | 坦米尔 |
| ta-IN | 坦米尔 -印度 |
| tt | Tatar |
| tt-RU | Tatar-俄国 |
| te | Telugu |
| te-IN | Telugu-印度 |
| th | 泰国 |
| th-TH | 泰国 -泰国 |
| tr | 土耳其语 |
| tr-TR | 土耳其语 -土耳其 |
| uk | 乌克兰 |
| uk-UA | 乌克兰 -乌克兰 |
| ur | Urdu |
| ur-PK | Urdu-巴基斯坦 |
| uz | Uzbek |
| uz-UZ-Cyrl | Uzbek-(西里尔字母的) 乌兹别克斯坦 |
| uz-UZ-Latn | Uzbek(拉丁文)- 乌兹别克斯坦 |
| vi | 越南 |
| vi-VN | 越南 -越南 |
| Countries and Regions | 国家或地区 | 国际域名缩写 | 电话代码 | |
| Angola | 安哥拉 | AO | 244 | |
| Afghanistan | 阿富汗 | AF | 93 | |
| Albania | 阿尔巴尼亚 | AL | 355 | |
| Algeria | 阿尔及利亚 | DZ | 213 | |
| Andorra | 安道尔共和国 | AD | 376 | |
| Anguilla | 安圭拉岛 | AI | 1264 | |
| Antigua and Barbuda | 安提瓜和巴布达 | AG | 1268 | |
| Argentina | 阿根廷 | AR | 54 | |
| Armenia | 亚美尼亚 | AM | 374 | |
| Ascension | 阿森松 | 247 | ||
| Australia | 澳大利亚 | AU | 61 | |
| Austria | 奥地利 | AT | 43 | |
| Azerbaijan | 阿塞拜疆 | AZ | 994 | |
| Bahamas | 巴哈马 | BS | 1242 | |
| Bahrain | 巴林 | BH | 973 | |
| Bangladesh | 孟加拉国 | BD | 880 | |
| Barbados | 巴巴多斯 | BB | 1246 | |
| Belarus | 白俄罗斯 | BY | 375 | |
| Belgium | 比利时 | BE | 32 | |
| Belize | 伯利兹 | BZ | 501 | |
| Benin | 贝宁 | BJ | 229 | |
| Bermuda Is. | 百慕大群岛 | BM | 1441 | |
| Bolivia | 玻利维亚 | BO | 591 | |
| Botswana | 博茨瓦纳 | BW | 267 | |
| Brazil | 巴西 | BR | 55 | |
| Brunei | 文莱 | BN | 673 | |
| Bulgaria | 保加利亚 | BG | 359 | |
| Burkina-faso | 布基纳法索 | BF | 226 | |
| Burma | 缅甸 | MM | 95 | |
| Burundi | 布隆迪 | BI | 257 | |
| Cameroon | 喀麦隆 | CM | 237 | |
| Canada | 加拿大 | CA | 1 | |
| Cayman Is. | 开曼群岛 | 1345 | ||
| Central African Republic | 中非共和国 | CF | 236 | |
| Chad | 乍得 | TD | 235 | |
| Chile | 智利 | CL | 56 | |
| China | 中国 | CN | 86 | |
| Colombia | 哥伦比亚 | CO | 57 | |
| Congo | 刚果 | CG | 242 | |
| Cook Is. | 库克群岛 | CK | 682 | |
| Costa Rica | 哥斯达黎加 | CR | 506 | |
| Cuba | 古巴 | CU | 53 | |
| Cyprus | 塞浦路斯 | CY | 357 | |
| Czech Republic | 捷克 | CZ | 420 | |
| Denmark | 丹麦 | DK | 45 | |
| Djibouti | 吉布提 | DJ | 253 | |
| Dominica Rep. | 多米尼加共和国 | DO | 1890 | |
| Ecuador | 厄瓜多尔 | EC | 593 | |
| Egypt | 埃及 | EG | 20 | |
| EI Salvador | 萨尔瓦多 | SV | 503 | |
| Estonia | 爱沙尼亚 | EE | 372 | |
| Ethiopia | 埃塞俄比亚 | ET | 251 | |
| Fiji | 斐济 | FJ | 679 | |
| Finland | 芬兰 | FI | 358 | |
| France | 法国 | FR | 33 | |
| French Guiana | 法属圭亚那 | GF | 594 | |
| Gabon | 加蓬 | GA | 241 | |
| Gambia | 冈比亚 | GM | 220 | |
| Georgia | 格鲁吉亚 | GE | 995 | |
| Germany | 德国 | DE | 49 | |
| Ghana | 加纳 | GH | 233 | |
| Gibraltar | 直布罗陀 | GI | 350 | |
| Greece | 希腊 | GR | 30 | |
| Grenada | 格林纳达 | GD | 1809 | |
| Guam | 关岛 | GU | 1671 | |
| Guatemala | 危地马拉 | GT | 502 | |
| Guinea | 几内亚 | GN | 224 | |
| Guyana | 圭亚那 | GY | 592 | |
| Haiti | 海地 | HT | 509 | |
| Honduras | 洪都拉斯 | HN | 504 | |
| Hongkong | 香港 | HK | 852 | |
| Hungary | 匈牙利 | HU | 36 | |
| Iceland | 冰岛 | IS | 354 | |
| India | 印度 | IN | 91 | |
| Indonesia | 印度尼西亚 | ID | 62 | |
| Iran | 伊朗 | IR | 98 | |
| Iraq | 伊拉克 | IQ | 964 | |
| Ireland | 爱尔兰 | IE | 353 | |
| Israel | 以色列 | IL | 972 | |
| Italy | 意大利 | IT | 39 | |
| Ivory Coast | 科特迪瓦 | 225 | ||
| Jamaica | 牙买加 | JM | 1876 | |
| Japan | 日本 | JP | 81 | |
| Jordan | 约旦 | JO | 962 | |
| Kampuchea (Cambodia ) | 柬埔寨 | KH | 855 | |
| Kazakstan | 哈萨克斯坦 | KZ | 327 | |
| Kenya | 肯尼亚 | KE | 254 | |
| Korea | 韩国 | KR | 82 | |
| Kuwait | 科威特 | KW | 965 | |
| Kyrgyzstan | 吉尔吉斯坦 | KG | 331 | |
| Laos | 老挝 | LA | 856 | |
| Latvia | 拉脱维亚 | LV | 371 | |
| Lebanon | 黎巴嫩 | LB | 961 | |
| Lesotho | 莱索托 | LS | 266 | |
| Liberia | 利比里亚 | LR | 231 | |
| Libya | 利比亚 | LY | 218 | |
| Liechtenstein | 列支敦士登 | LI | 423 | |
| Lithuania | 立陶宛 | LT | 370 | |
| Luxembourg | 卢森堡 | LU | 352 | |
| Macao | 澳门 | MO | 853 | |
| Madagascar | 马达加斯加 | MG | 261 | |
| Malawi | 马拉维 | MW | 265 | |
| Malaysia | 马来西亚 | MY | 60 | |
| Maldives | 马尔代夫 | MV | 960 | |
| Mali | 马里 | ML | 223 | |
| Malta | 马耳他 | MT | 356 | |
| Mariana Is | 马里亚那群岛 | 1670 | ||
| Martinique | 马提尼克 | 596 | ||
| Mauritius | 毛里求斯 | MU | 230 | |
| Mexico | 墨西哥 | MX | 52 | |
| Moldova, Republic of | 摩尔多瓦 | MD | 373 | |
| Monaco | 摩纳哥 | MC | 377 | |
| Mongolia | 蒙古 | MN | 976 | |
| Montserrat Is | 蒙特塞拉特岛 | MS | 1664 | |
| Morocco | 摩洛哥 | MA | 212 | |
| Mozambique | 莫桑比克 | MZ | 258 | |
| Namibia | 纳米比亚 | NA | 264 | |
| Nauru | 瑙鲁 | NR | 674 | |
| Nepal | 尼泊尔 | NP | 977 | |
| Netheriands Antilles | 荷属安的列斯 | 599 | ||
| Netherlands | 荷兰 | NL | 31 | |
| New Zealand | 新西兰 | NZ | 64 | |
| Nicaragua | 尼加拉瓜 | NI | 505 | |
| Niger | 尼日尔 | NE | 227 | |
| Nigeria | 尼日利亚 | NG | 234 | |
| North Korea | 朝鲜 | KP | 850 | |
| Norway | 挪威 | NO | 47 | |
| Oman | 阿曼 | OM | 968 | |
| Pakistan | 巴基斯坦 | PK | 92 | |
| Panama | 巴拿马 | PA | 507 | |
| Papua New Cuinea | 巴布亚新几内亚 | PG | 675 | |
| Paraguay | 巴拉圭 | PY | 595 | |
| Peru | 秘鲁 | PE | 51 | |
| Philippines | 菲律宾 | PH | 63 | |
| Poland | 波兰 | PL | 48 | |
| French Polynesia | 法属玻利尼西亚 | PF | 689 | |
| Portugal | 葡萄牙 | PT | 351 | |
| Puerto Rico | 波多黎各 | PR | 1787 | |
| Qatar | 卡塔尔 | QA | 974 | |
| Reunion | 留尼旺 | 262 | ||
| Romania | 罗马尼亚 | RO | 40 | |
| Russia | 俄罗斯 | RU | 7 | |
| Saint Lueia | 圣卢西亚 | LC | 1758 | |
| Saint Vincent | 圣文森特岛 | VC | 1784 | |
| Samoa Eastern | 东萨摩亚(美) | 684 | ||
| Samoa Western | 西萨摩亚 | 685 | ||
| San Marino | 圣马力诺 | SM | 378 | |
| Sao Tome and Principe | 圣多美和普林西比 | ST | 239 | |
| Saudi Arabia | 沙特阿拉伯 | SA | 966 | |
| Senegal | 塞内加尔 | SN | 221 | |
| Seychelles | 塞舌尔 | SC | 248 | |
| Sierra Leone | 塞拉利昂 | SL | 232 | |
| Singapore | 新加坡 | SG | 65 | |
| Slovakia | 斯洛伐克 | SK | 421 | |
| Slovenia | 斯洛文尼亚 | SI | 386 | |
| Solomon Is | 所罗门群岛 | SB | 677 | |
| Somali | 索马里 | SO | 252 | |
| South Africa | 南非 | ZA | 27 | |
| Spain | 西班牙 | ES | 34 | |
| Sri Lanka | 斯里兰卡 | LK | 94 | |
| St.Lucia | 圣卢西亚 | LC | 1758 | |
| St.Vincent | 圣文森特 | VC | 1784 | |
| Sudan | 苏丹 | SD | 249 | |
| Suriname | 苏里南 | SR | 597 | |
| Swaziland | 斯威士兰 | SZ | 268 | |
| Sweden | 瑞典 | SE | 46 | |
| Switzerland | 瑞士 | CH | 41 | |
| Syria | 叙利亚 | SY | 963 | |
| Taiwan | 台湾省 | TW | 886 | |
| Tajikstan | 塔吉克斯坦 | TJ | 992 | |
| Tanzania | 坦桑尼亚 | TZ | 255 | |
| Thailand | 泰国 | TH | 66 | |
| Togo | 多哥 | TG | 228 | |
| Tonga | 汤加 | TO | 676 | |
| Trinidad and Tobago | 特立尼达和多巴哥 | TT | 1809 | |
| Tunisia | 突尼斯 | TN | 216 | |
| Turkey | 土耳其 | TR | 90 | |
| Turkmenistan | 土库曼斯坦 | TM | 993 | |
| Uganda | 乌干达 | UG | 256 | |
| Ukraine | 乌克兰 | UA | 380 | |
| United Arab Emirates | 阿拉伯联合酋长国 | AE | 971 | |
| United Kiongdom | 英国 | GB | 44 | |
| United States of America | 美国 | US | 1 | |
| Uruguay | 乌拉圭 | UY | 598 | |
| Uzbekistan | 乌兹别克斯坦 | UZ | 233 | |
| Venezuela | 委内瑞拉 | VE | 58 | |
| Vietnam | 越南 | VN | 84 | |
| Yemen | 也门 | YE | 967 | |
| Yugoslavia | 南斯拉夫 | YU | 381 | |
| Zimbabwe | 津巴布韦 | ZW | 263 | |
| Zaire | 扎伊尔 | ZR | 243 | |
| Zambia | 赞比亚 | ZM | 260 |
...
1xx(临时响应)
表示临时响应并需要请求者继续执行操作的状态代码。
代码 说明
100 (继续) 请求者应当继续提出请求。 服务器返回此代码表示已收到请求的第一部分,正在等待其余部分。
101 (切换协议) 请求者已要求服务器切换协议,服务器已确认并准备切换。
2xx (成功)
表示成功处理了请求的状态代码。
代码 说明
200 (成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。
201 (已创建) 请求成功并且服务器创建了新的资源。
202 (已接受) 服务器已接受请求,但尚未处理。
203 (非授权信息) 服务器已成功处理了请求,但返回的信息可能来自另一来源。
204 (无内容) 服务器成功处理了请求,但没有返回任何内容。
205 (重置内容) 服务器成功处理了请求,但没有返回任何内容。
206 (部分内容) 服务器成功处理了部分 GET 请求。
3xx (重定向)
表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向。
代码 说明
300 (多种选择) 针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。
301 (永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
302 (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
303 (查看其他位置) 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。
304 (未修改) 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。
305 (使用代理) 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。
307 (临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
4xx(请求错误)
这些状态代码表示请求可能出错,妨碍了服务器的处理。
代码 说明
400 (错误请求) 服务器不理解请求的语法。
401 (未授权) 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。
403 (禁止) 服务器拒绝请求。
404 (未找到) 服务器找不到请求的网页。
405 (方法禁用) 禁用请求中指定的方法。
406 (不接受) 无法使用请求的内容特性响应请求的网页。
407 (需要代理授权) 此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理。
408 (请求超时) 服务器等候请求时发生超时。
409 (冲突) 服务器在完成请求时发生冲突。 服务器必须在响应中包含有关冲突的信息。
410 (已删除) 如果请求的资源已永久删除,服务器就会返回此响应。
411 (需要有效长度) 服务器不接受不含有效内容长度标头字段的请求。
412 (未满足前提条件) 服务器未满足请求者在请求中设置的其中一个前提条件。
413 (请求实体过大) 服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。
414 (请求的 URI 过长) 请求的 URI(通常为网址)过长,服务器无法处理。
415 (不支持的媒体类型) 请求的格式不受请求页面的支持。
416 (请求范围不符合要求) 如果页面无法提供请求的范围,则服务器会返回此状态代码。
417 (未满足期望值) 服务器未满足”期望”请求标头字段的要求。
5xx(服务器错误)
这些状态代码表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身的错误,而不是请求出错。
代码 说明
500 (服务器内部错误) 服务器遇到错误,无法完成请求。
501 (尚未实施) 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。
502 (错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。
503 (服务不可用) 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。
504 (网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。
505 (HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。
RFC 6585 最近刚刚发布,该文档描述了 4 个新的 HTTP 状态码。
HTTP 协议还在变化?是的,HTTP 协议一直在演变,新的状态码对于开发 REST 服务或者说是基于 HTTP 的服务非常有用,下面我们为你详细介绍这四个新的状态码以及是否应该使用。
先决条件是客户端发送 HTTP 请求时,如果想要请求能成功必须满足一些预设的条件。
一个好的例子就是 If-None-Match 头,经常在 GET 请求中使用,如果指定了 If-None-Match ,那么客户端只在响应中的 ETag 改变后才会重新接收回应。
先决条件的另外一个例子就是 If-Match 头,这个一般用在 PUT 请求上用于指示只更新没被改变的资源,这在多个客户端使用 HTTP 服务时用来防止彼此间不会覆盖相同内容。
当服务器端使用 428 Precondition Required 状态码时,表示客户端必须发送上述的请求头才能执行请求,这个方法为服务器提供一种有效的方法来阻止 'lost update' 问题。
当你需要限制客户端请求某个服务数量时,该状态码就很有用,也就是请求速度限制。
在此之前,有一些类似的状态码,例如 '509 Bandwidth Limit Exceeded'. Twitter 使用 420 (这不是HTTP定义的状态码)
如果你希望限制客户端对服务的请求数,可使用 429 状态码,同时包含一个 Retry-After 响应头用于告诉客户端多长时间后可以再次请求服务。
某些情况下,客户端发送 HTTP 请求头会变得很大,那么服务器可发送 431 Request Header Fields Too Large 来指明该问题。
我不太清楚为什么没有 430 状态码,而是直接从 429 跳到 431,我尝试搜索但没有结果。唯一的猜测是 430 Forbidden 跟 403 Forbidden 太像了,为了避免混淆才这么做的,天知道!
对我来说这个状态码很有趣,如果你在开发一个 HTTP 服务器,你不一定需要处理该状态码,但如果你在编写 HTTP 客户端,那这个状态码就非常重要。
如果你频繁使用笔记本和智能手机,你可能会注意到大量的公用 WIFI 服务要求你必须接受一些协议或者必须登录后才能使用。
这是通过拦截HTTP流量,当用户试图访问网络返回一个重定向和登录,这很讨厌,但是实际情况就是这样的。
使用这些“拦截”客户端,会有一些讨厌的副作用。在 RFC 中有提到这两个的例子:
因此 511 状态码的提出就是为了解决这个问题。
如果你正在编写 HTTP 的客户端,你最好还是检查 511 状态码以确认是否需要认证后才能访问。
...
支持DKIM校验的C#发送
Adf.dll 4.6.2.30867 可支持 DKIM 邮件发送
DKIM 密钥可通过 http://dkimcore.org/tools/ 生成
并按要求设置好DNS
发送示例如:
var host = "192.168.199.10";
var port = 25;
//设置发送与接收人员
var from = "e4ed22af7@example.com";
var to = "4234523@qq.com";
to = "test-763047a4@appmaildev.com";
//定义签名域
var domain = "example.com";
var selector = "dkim201701";
//初始dkim对象, 此对象可用于多个MailMessage对象
var dkim = new Adf.Mail.DKIM(domain, selector);
dkim.LoadKey(@"-----BEGIN RSA PRIVATE KEY-----
MIICXQIBAAKBgQCxcjbutjZfE1trW5oFt7t4AnjDRHeHwbi2AGE5n1M8YZSO2fGi
fBnsSy/qNoaKwoROhNl9S0mya7Q5odloyN3IEVoUCZjnd3onTsZ4vmXD/Ei4r0+S
...
ba3kqofe7BP7QpMwqZmLALDngIp4htRrTYFehzZ6zavB
-----END RSA PRIVATE KEY-----
");
//邮件体
var message = new Adf.Mail.MailMessage();
message.Subject = "You password expired";
message.IsBodyHtml = false;
message.Body = @"hi\r\nyou password expired, please check.\r\n\r\n services.";
message.From = new Adf.Mail.MailAddress(from);
message.To.Add(new Adf.Mail.MailAddress(to));
//为一个邮件集设置DKIM对象
message.Dkim = dkim;
//发送邮件
using (var smtpClient = new Adf.Mail.SmtpClient(host, port))
{
smtpClient.Send(message);
}
...
本文简要介绍Adf.QueueServer的一些常规应用和协议。
本服务支持 WebSocket Json/ WebSocket Binary / HTTP Json 三种通信方式
一般使用 WebSocket 做异步push/pull, 使用HTTP做同步push/pull
若同时使用多种格式JSON/BINARY,需要注意消息体(body)是否可以通过UTF8编码于二进制与字符串之间相互转化,否则可能会出现乱码情况。理论上同一队列应尽量保持使用同一种格式传输。
本服务为FIFO QUEUE,消息将保持顺序PULL,在单线程消费下消息与业务均保持顺序性。在多终端或多线程或多PULL下、消息保持顺序PULl但不保证业务执行的顺序性。
本服务支持命令:
| rpush | 队列右侧插入一项 |
| lpush | 队列左侧插入一项 |
| pull | 从队列中获取最左侧一项 |
| delete | 删除已从队列中pull过的项,未被pull过的项不可被删除 |
| lcancel | 恢复已pull过的项至队列左侧 |
| rcancel | 恢复已pull过的项至队列右侧 |
| count | 查询队列长度 |
| clear | 清空队列项 |
字符编码格式: UTF8
//push request:
{
"action":"lpush/rpush",
"requestid":"1 ~ 32 chr. propose use uuid",
"queue": "/order/new",
"body":"this is a test message."
}
//push response:
{
"action":"lpush/rpush",
"requestid":"88bea088837d4743af67a2d49e6d08d1",
"queue": "/order/new",
"result":"ok or failure message",
"messageid": 1452443242
}
//delete/lcancel/rcancel/createqueue/deletequeue/count/clear/pull request:
{
"action":"delete/lcancel/rcancel/createqueue/deletequeue/count/clear/pull",
"requestid":"1 ~ 32 chr. propose use uuid",
"queue": "/order/new"
}
//delete/lcancel/rcancel/createqueue/deletequeue response:
{
"action":"delete/lcancel/rcancel/createqueue/deletequeue",
"requestid":"88bea088837d4743af67a2d49e6d08d1",
"queue": "/order/new",
"result":"ok or failure message"
}
//count/clear response:
{
"action":"count/clear",
"requestid":"88bea088837d4743af67a2d49e6d08d1",
"queue": "/order/new",
"result":"ok or failure message",
"count":0
}
//pull response:
{
"action":"pull",
"requestid":"88bea088837d4743af67a2d49e6d08d1",
"queue": "/order/new",
"result":"ok or failure message",
"body":"message body.",
"duplications": 0,
"messageid": 1452443242
}
Endianness : Big-Endian
Body: UTF8
二进制元素内容与JSON结构一致。
//type: action : byte xx length : uint16 duplications: uint16 count : int32 messageid : uint64 //push request: +---------------------------------------------------------------+ | action (1) +---------------------------------------------------------------+ | id length (2) +---------------------------------------------------------------+ | id (1 ~ 65535) +---------------------------------------------------------------+ | queue length (2) +---------------------------------------------------------------+ | queue (1 ~ 65535) +---------------------------------------------------------------+ | body length (2) +---------------------------------------------------------------+ | body (1 ~ 65535) +---------------------------------------------------------------+ //push response: +---------------------------------------------------------------+ | action (1) +---------------------------------------------------------------+ | id length (2) +---------------------------------------------------------------+ | id (1 ~ 65535) +---------------------------------------------------------------+ | queue length (2) +---------------------------------------------------------------+ | queue (1 ~ 65535) +---------------------------------------------------------------+ | result length (2) +---------------------------------------------------------------+ | result (1 ~ 65535) +---------------------------------------------------------------+ | OK | messageid length (8) +---------------------------------------------------------------+ //delete/lcancel/rcancel/createqueue/deletequeue/count/clear/pull request: +---------------------------------------------------------------+ | action (1) +---------------------------------------------------------------+ | id length (2) +---------------------------------------------------------------+ | id (1 ~ 65535) +---------------------------------------------------------------+ | queue length (2) +---------------------------------------------------------------+ | queue (1 ~ 65535) +---------------------------------------------------------------+ //delete/lcancel/rcancel/createqueue/deletequeue response: +---------------------------------------------------------------+ | action (1) +---------------------------------------------------------------+ | id length (2) +---------------------------------------------------------------+ | id (1 ~ 65535) +---------------------------------------------------------------+ | queue length (2) +---------------------------------------------------------------+ | queue (1 ~ 65535) +---------------------------------------------------------------+ | result length (2) +---------------------------------------------------------------+ | result (1 ~ 65535) +---------------------------------------------------------------+ //count/clear response: +---------------------------------------------------------------+ | action (1) +---------------------------------------------------------------+ | id length (2) +---------------------------------------------------------------+ | id (1 ~ 65535) +---------------------------------------------------------------+ | queue length (2) +---------------------------------------------------------------+ | queue (1 ~ 65535) +---------------------------------------------------------------+ | result length (2) +---------------------------------------------------------------+ | result (1 ~ 65535) +---------------------------------------------------------------+ | OK | count (4) +---------------------------------------------------------------+ //pull response: +---------------------------------------------------------------+ | action (1) +---------------------------------------------------------------+ | id length (2) +---------------------------------------------------------------+ | id (1 ~ 65535) +---------------------------------------------------------------+ | queue length (2) +---------------------------------------------------------------+ | queue (1 ~ 65535) +---------------------------------------------------------------+ | result length (2) +---------------------------------------------------------------+ | result (1 ~ 65535) +---------------------------------------------------------------+ | | body length (2) + -----------------------------------------------------------+ | | body (1 ~ 65535) + OK -----------------------------------------------------------+ | | duplications (2) + -----------------------------------------------------------+ | | messageid (8) +---------------------------------------------------------------+
字符编码: UTF8
元素与JSON结构一致,但在请求时除rpush/lpush时的body以外,其它所有元素均以Queue String方式进行传递。
返回结果与同JSON结构
以.json后缀的接口,返回JSON
以.bin 后缀的接口,返回二进制数据
| PATH | METHOD | REMARKS |
| /queue/rpush.json?queue=&requestid= /queue/rpush.bin?queue=&requestid= |
POST | application/octet-stream 内容为消息实体BODY |
| /queue/lpush.json?queue=&requestid= /queue/lpush.bin?queue=&requestid= |
POST | application/octet-stream 内容为消息实体BODY |
| /queue/pull.json?queue=&requestid= /queue/pull.bin?queue=&requestid= |
GET | 拉取一个消息 |
| /queue/delete.json?queue=&requestid= /queue/delete.bin?queue=&requestid= |
GET | 删除一个已拉取消息 |
| /queue/lcancel.json?queue=&requestid= /queue/lcancel.bin?queue=&requestid= |
GET | 恢复一个已拉取消息至队列左侧 |
| /queue/rcancel.json?queue=&requestid= /queue/rcancel.bin?queue=&requestid= |
GET | 恢复一个已拉取消息至队列右侧 |
| /queue/count.json?queue=&requestid= /queue/count.bin?queue=&requestid= |
GET | 获取一个队列元素数 |
| /queue/clear.json?queue=&requestid= /queue/clear.bin?queue=&requestid= |
GET | 清空一个队列元素 |
Binary ws://{host}:{port}/queue/bin
Json ws://{host}:{port}/queue/json
同一个ws连接允许同时多个PULL请求。
协议中 RequestID 为请求标识,不做为消息标识,该标识由使用者自行生成,可以是1-32位字符,除PULL以外的其它所有命令均允许该体重复。
在PULL时若使用websocket则必需保证同一连接中不重复,常在同一连接中使用递增数做为标识。若使用http则需保证http全局不重复。 不能重复是因为PULL的标识需在要delete/lcancel/rcancel时做为识别标识使用。
编码如下
const byte LPUSH = 1; const byte RPUSH = 2; const byte DELETE = 3; const byte PULL = 4; const byte CLEAR = 5; const byte COUNT = 6; const byte LCANCEL = 7; const byte RCANCEL = 8; const byte CREATEQUEUE = 9; const byte DELETEQUEUE = 10; const string OK = "ok";
本服务原生支持事务模式, 不支持非事务模式的消息消费,所有消息在消费后必需通过delete命令删除;
若终端在处理业务时认为是一个失败的业务消费可以通过lcancel/rcancel将消息退回至队列的左侧或右侧;
面向连接使用方式,若不进行delete操作,则在连接断开后将自动恢复至队列左侧;
消息每被退回后再次PULL一次则duplications将为递增1,通常可以通过该值来判断该消息是否为被初次消费,若不是被初次消费则应检查重复消费所导致的脏数据或重复数据,如:不应产生两次相同的订单或扣款。
1) Authenticated With Signatures
主模式:
Initiator Responder
----------- -----------
HDR, SA -->
<-- HDR, SA
HDR, KE, Ni -->
<-- HDR, KE, Nr
HDR*, IDii, [ CERT, ] SIG_I -->
<-- HDR*, IDir, [ CERT, ] SIG_R
野蛮模式:
Initiator Responder
----------- -----------
HDR, SA, KE, Ni, IDii -->
<-- HDR, SA, KE, Nr,
IDir, [ CERT, ]
SIG_RHDR, [ CERT, ]
SIG_I -->
2) Authenticated With Public Key Encryption
主模式:
Initiator Responder
----------- -----------
HDR, SA -->
<-- HDR, SA
HDR, KE, [ HASH(1), ]
PubKey_r,
PubKey_r -->
HDR, KE, PubKey_i,
<-- PubKey_i
HDR*, HASH_I -->
<-- HDR*, HASH_R
野蛮模式:
Initiator Responder
----------- -----------
HDR, SA, [ HASH(1),] KE,
Pubkey_r,
Pubkey_r -->
HDR, SA, KE, PubKey_i,
<-- PubKey_i, HASH_R
HDR, HASH_I -->
3) Authenticated With a Revised Mode of Public Key Encryption
主模式:
Initiator Responder
----------- -----------
HDR, SA -->
<-- HDR, SA
HDR, [ HASH(1), ]
Pubkey_r,
Ke_i,
Ke_i,
[<Ke_i] -->
HDR, PubKey_i,
Ke_r,
<-- Ke_r,
HDR*, HASH_I -->
<-- HDR*, HASH_R
野蛮模式:
Initiator Responder
----------- -----------
HDR, SA, [ HASH(1),]
Pubkey_r,
Ke_i, Ke_i
[, Ke_i ] -->
HDR, SA, PubKey_i,
Ke_r, Ke_r,
<-- HASH_R
HDR, HASH_I -->
4) Authenticated With a Pre-Shared Key
主模式:
Initiator Responder
---------- -----------
HDR, SA -->
<-- HDR, SA
HDR, KE, Ni -->
<-- HDR, KE, Nr
HDR*, IDii, HASH_I -->
<-- HDR*, IDir, HASH_R
野蛮模式:
Initiator Responder
----------- -----------
HDR, SA, KE, Ni, IDii -->
<-- HDR, SA, KE, Nr, IDir, HASH_R
HDR, HASH_I -->
2.3 第二阶段
快速模式:
Initiator Responder
----------- -----------
HDR*, HASH(1), SA, Ni
[, KE ] [, IDci, IDcr ] -->
<-- HDR*, HASH(2), SA, Nr
[, KE ] [, IDci, IDcr ]
HDR*, HASH(3) -->
如果有多个SA和密钥可使用下面的数据交换方法:
Initiator Responder
----------- -----------
HDR*, HASH(1), SA0, SA1, Ni,
[, KE ] [, IDci, IDcr ] -->
<-- HDR*, HASH(2), SA0, SA1, Nr,
[, KE ] [, IDci, IDcr ]
HDR*, HASH(3) -->
HASH(1) = prf(SKEYID_a, M-ID | SA | Ni [ | KE ] [ | IDci | IDcr )
HASH(2) = prf(SKEYID_a, M-ID | Ni_b | SA | Nr [ | KE ] [ | IDci | IDcr )
HASH(3) = prf(SKEYID_a, 0 | M-ID | Ni_b | Nr_b)
2.4 新组模式(New Group Mode)
新组模式不是必须实现的, 是用来定义DH交换的私有组的, 必须在ISAKMP SA建立前使用, 也就是在第一阶段后, 第二阶段前。
Initiator Responder
----------- -----------
HDR*, HASH(1), SA -->
<-- HDR*, HASH(2), SA
HASH(1) = prf(SKEYID_a, M-ID | SA)
HASH(2) = prf(SKEYID_a, M-ID | SA)
OpenVPN 下载地址: http://openvpn.net
查看系统版本
cat /etc/redhat-release
CentOS release 6.5 (Final)
查看内核和cpu架构
uname -rm
2.6.32-431.el6.x86_64 x86_64
查看ip
ifconfig
eth0 Link encap:Ethernet HWaddr 08:00:27:5E:DF:74
inet addr:xxx.xxx.xxx.xxx Bcast:xxx.xxx.xxx.255 Mask:255.255.255.0
inet6 addr: fe80::a00:27ff:fe5e:df74/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:457 errors:0 dropped:0 overruns:0 frame:0
TX packets:55 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:37261 (36.3 KiB) TX bytes:6438 (6.2 KiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
#使用单网卡
添加epel源
rpm -ivh http://dl.fedoraproject.org/pub/epel/5/i386/epel-release-5-4.noarch.rpm
安装openvpn和easy-rsa
yum -y install openvpn easy-rsa
拷贝文件
cp /usr/share/doc/openvpn-2.3.10/sample/sample-config-files/server.conf /etc/openvpn
cp -r /usr/share/easy-rsa/2.0/* /etc/openvpn/
进入openvpn目录
cd /etc/openvpn/
配置PKI
vi vars
编辑下面内容,自定义。
export KEY_COUNTRY="CN"
export KEY_PROVINCE="guangdong"
export KEY_CITY="guangzhou"
export KEY_ORG="xxx"
export KEY_EMAIL="xxx@qq.com"
export KEY_OU="xxx"
初始化vars
source vars
清理原有证书
./clean-all
生成ca证书
./build-ca
#一路按回车键
生成服务器密钥证书
./build-key-server server
#一路按回车键,两次按y
生成DH验证文件
./build-dh
生成客户端密钥证书
./build-key xxx
#一路按回车键,两次按y
生成ta.key文件
openvpn --genkey --secret /etc/openvpn/keys/ta.key
编辑服务配置文件server.conf
vi /etc/openvpn/server.conf
主要修改以下内容:
port 1194
proto udp
dev tun
ca keys/ca.crt
cert keys/server.crt
key keys/server.key
dh keys/dh2048.pem
server 10.8.0.0 255.255.255.0
push "dhcp-option DNS 8.8.8.8"
push "dhcp-option DNS 8.8.4.4"
log-append /var/log/openvpn/openvpn.log
#我采用的是相对路径
新建日志目录
mkdir -p /var/log/openvpn
启动openvpn服务
service openvpn start
新手一般都会在这一步启动不了,但是重要的是要学会通过查看日志排错。
cat /var/log/openvpn/openvpn.log
添加openvpn到后台启动
chkconfig openvpn on
开启路由转发功能
sed -i '/net.ipv4.ip_forward/s/0/1/' /etc/sysctl.conf
sysctl -p
配置防火墙让openvpn端口通过
iptables -A INPUT -p UDP --dport 1194 -j ACCEPT
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables -t nat -A POSTROUTING -o eth0 -s 10.8.0.0/24 -j MASQUERADE
service iptables save
客户端文件配置
cp /usr/share/doc/openvpn-2.3.10/sample/sample-config-files/client.conf /etc/openvpn/keys/client.ovpn
vi /etc/openvpn/keys/client.ovpn
主要修改以下内容:
dev tun
proto udp
remote xxx.xxx.xxx.xxx 1194 #ip为服务器网卡的ip
ca ca.crt
cert xxx.crt
key xxx.key
#以上证书路径均为相对路径
将客户端所需的五个文件下载到本地
sz /etc/openvpn/keys/{ca.crt,xxx.crt,xxx.key,ta.key,client.ovpn}
下载windows客户端并安装
https://openvpn.net/index.php/open-source/downloads.html
将之前下载的五个文件拷贝到C:/Program Files/OpenVPN/config目录下,双击桌面openvpn图标就ok了。
添加新用户
以上仅生成了一个 xxx 用户, 仅一用户可用,可以用相同的方法添加其它用户。
1: cd /etc/openvpn/easy-rsa/2.0
2: source vars
PS:如果不执行这步,执行第三步./build-key 会导致如下问题:
Please edit the vars script to reflect your configuration,
then source it with "source ./vars".
Next, to start with a fresh PKI configuration and to delete any
previous certificates and keys, run "./clean-all".
Finally, you can run this tool (pkitool) to build certificates/keys.
3: ./build-key client2
执行完这步后,会在keys目录下生成client2.crt client2.key两个文件。
同第一个用户一样,将此两个文件与ca.crt,ta.key文件一同拷贝到使用者设备上即可使用。
4: 创建对应的 client2.ovpn
可直接拷贝第一个生成的ovpn或从示例中复制, 替换其中的 client2.crt 与 client2.key 即可。
注销一个用户
例如一位同事离职等情况下需要禁用或删除一个用户。使用revoke-full命令来注销其证书。若服务器上无用户证书需要将该同事证书文件放到对应的keys下。
第1,2步同添加用户
1: cd /etc/openvpn/easy-rsa/2.0
2: source vars
3: revoke-full client1
注销common name为client1的用户
revoke-full client2
注销common name为client2的用户
revoke-full xxxx
注销common name为xxxx的用户
4: 将生成的crl.pem文件放到相应的配置目录config下,然后在配置文件加入如下参数,重启或重新载入openvpn服务器
crl-verify keys/crl.pem
本文简要介绍Adf.NumberServer在windows平台下的使用。
本服务常用于生成用户标识,订单标识,会话标识等场景。
服务完全兼容 memcached 文本协议, 使用支持1.2.0 或以上版本的任意一款客户端均可访问,不区分语言,本服务仅支持 set,incr,decr,get,stats 五个命令,其它命令均不受支持。
Protocol:
https://github.com/memcached/memcached/blob/1.6.0-beta1/doc/protocol.txt
根据协议:
incr 可至int64最大值,超过最大值后将会归零后循环,
decr 可至最小值0,低于0值时会保持0值,不会出现负数。
本服务支持最长KEY为 250字符, 超过该长度服务将会出现异常。
本服务不支持多字节KEY, 仅支持ASCII字符。
在数据不要求安全的情况下,本服务支持单机模式。
单机模式时需要将配置文件中所有以HA:方式开始的配置禁用或删除掉。
本服务基于 adf.service 组件, 支持master/slave/witness 的高可用方式,为提高可用性,master与slave通信为实时同步而保持数据的绝对一致性。
启用HA需配置:
HA:Path 高可用配置数据存储路径
HA:Node1 默认的master服务
HA:Node2 默认的slave服务
HA:Node3 默认的witness 服务
注意:本服务在高可用环境时, 只有master会对外提供服务,其它两个节点不会对外提供服务,因此,你的客户端需要能自动的判断节点的可用性。
本服务允许你直接停掉master主机来进行手动的主备切换,主机停止后slave将自动成为master以提供服务。
当有需要再次启动原master时,原master节点将会以slave成员启动。
注意:你不能手动的频繁来回切换,因为数据复制原因,你必需确定现slave成员的日志文件中出现 replication client: request replicate sync 日志后再进行回切, 否则有可能出现数据丢失。
通过以下连接下载:
http://www.aooshi.org/adf/download/Adf.NumberServer-2.0.0.zip
http://www.aooshi.org/adf/doc/adf.numberserver-2.0.0-manual.pdf
工具描述:
ToolInstallService 用于将应用以服务方式安装至系统
ToolRunConsole 手动运行应用
ToolUninstallService 用于卸载已安装在系统中的应用
区分大小写
| 名 | 值 |
| Port | 服务端口,默认为: 6224 |
| Ip | 允许配置本机IP或 * , * 表示当前设备的所有网络接口。 |
| DataPath | 数据存储路径 |
| Log:FlushInterval | 日志刷新间隔, 建议值: 5s |
| Log:Path | 日志存储路径。 |
| HA:Node1 | 高可用模式的Master节点 |
| HA:Node2 | 高可用模式的Slave节点 |
| HA:Node3 | 高可用模式的Witness节点 |
| HA:Keepalive | 高可用模式节点检测间隔,默认: 5s |
| HA:ElectTimeout | 高可用模式Master节点选举超时时间,默认:5s |
| HA:Mails | 高可用模式时 节点变化通知邮件收件人 |
在原服务协议基础上,增加模糊查询命令扩展。
get * {prefix} {size}
* 获取模糊匹配,第一个* 表示模糊匹配模式
prefix 表示需要匹配的键前缀
size 表示需要返回的条数
get * * 10
上述命令将获取所有键中的任意 10 条数据
get * * 100
上述命令将获取所有键中的任意 100 条数据
get * ab 10
上述命令将获取所有键以ab开始的的任意10 条数据
get * am 10
上述命令将获取所有键以am开始的的任意10 条数据
匹配: amaooshi, amtom
不匹配: name, toam
配置添加:
将下列配置中的IP地址更换为自已的
<configSections>
<section name="NumberServer" type="Adf.Config.IpGroupSection,Adf"/>
</configSections>
<NumberServer>
<!-- HA:Node1 -->
<add ip="192.168.199.14" port="6224"/>
<!-- HA:Node1 -->
<add ip="192.168.199.13" port="6224"/>
</NumberServer>
添加类:
| public class NumberServerClient : Adf.MemcachePool { public static readonly Adf.MemcachePool Instance = new Adf.MemcachePool("NumberServer"); } |
使用与示例:
| long userId = NumberServerClient.Instance.Increment("userid"); long userId = NumberServerClient.Instance.Increment("id.user.net.cn"); long productId = NumberServerClient.Instance.Increment("/product1/id"); long p2Id = NumberServerClient.Instance.Increment("/product2/id"); long p3Id = NumberServerClient.Instance.Increment("/product3/id"); long orderId = NumberServerClient.Instance.Increment("/order/id"); long bookId = NumberServerClient.Instance.Increment("/book/id"); long bookId = NumberServerClient.Instance.Increment("id.book.net.cn"); |
【黑体字的参数较为常用】
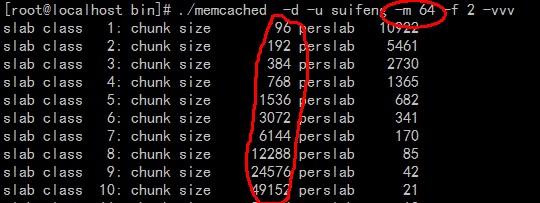
| -p<num> | 监听的TCP端口(默认:11211) |
| -U<num> | UDP监听端口(默认:11211 0关闭) |
| -d | 以守护进程方式运行 |
| -u<username> | 指定用户运行 |
| -m<num>. | 最大内存使用,单位MB。默认64MB |
| -c<num> | 最大同时连接数,默认是1024 |
| -v | 输出警告和错误消息 |
| -vv | 打印客户端的请求和返回信息 |
| -h | 帮助信息 |
| -l<ip> | 绑定地址(默认任何ip地址都可以访问) |
| -P<file> | 将PID保存在file文件 |
| -i | 打印memcached和libevent版权信息 |
| -M | 禁止LRU策略,内存耗尽时返回错误 |
| -f<factor> | 增长因子,默认1.25 |
| -n<bytes> | 初始chunk=key+suffix+value+32结构体,默认48字节 |
| -L | 启用大内存页,可以降低内存浪费,改进性能 |
| -l |
调整分配slab页的大小,默认1M,最小1k到128M |
| -t<num> |
线程数,默认4。由于memcached采用NIO,所以更多线程没有太多作用 |
| -R |
每个event连接最大并发数,默认20 |
| -C |
禁用CAS命令(可以禁止版本计数,减少开销) |
| -b |
Set the backlog queue limit (default: 1024) |
| -B |
Binding protocol-one of ascii, binary or auto (default) |
| -s<file> |
UNIX socket |
| -a<mask> |
access mask for UNIX socket, in octal (default: 0700) |
5、Memcache指令汇总
| 指令 | 描述 | 例子 |
| get key | #返回对应的value | get mykey |
| set key 标识符 有效时间 长度 | key不存在添加,存在更新 | set mykey 0 60 5 |
| add key标识符 有效时间 长度 | #添加key-value值,返回stored/not_stored | add mykey 0 60 5 |
| replace key标识符 有效时间 长度 | #替换key中的value,key存在成功返回stored,key不存在失败返回not_stored | replace mykey 0 60 5 |
| append key标识符 有效时间 长度 | #追加key中的value值,成功返回stored,失败返回not_stored | append mykey 0 60 5 |
| prepend key标识符 有效时间 长度 | #前置追加key中的value值,成功返回stored,失败返回not_stored | prepend mykey 0 60 5 |
| incr key num | #给key中的value增加num。若key中不是数字,则将使用num替换value值。返回增加后的value | Incre mykey 1 |
| decr | #同上 | 同上 |
| delete key [key2…] | 删除一个或者多个key-value。成功删除返回deleted,不存在失败则返回not_found | delete mykey |
| flush_all [timeount] | #清除所有[timeout时间内的]键值,但不会删除items,所以memcache依旧占用内存 | flush_all 20 |
| version | #返回版本号 | version |
| verbosity | #日志级别 | verbosity |
| quit | #关闭连接 | quit |
| stats | #返回Memcache通用统计信息 | stats |
| stats slabs | #返回Memcache运行期间创建的每个slab的信息 | stats slabs |
| stats items | #返回各个slab中item的个数,和最老的item秒数 | stats items |
| stats malloc | #显示内存分配数据 | stats malloc |
| stats detail [on|off|dump] | #on:打开详细操作记录、off:关闭详细操作记录、dump显示详细操作记录(每一个键的get、set、hit、del的次数) | stats detail on
stats detail off stats detail dump |
| stats cachedump slab_id limit_num | #显示slab_id中前limit_num个key | stats cachedump 1 2 |
| stats reset | #清空统计数据 | stats reset |
| stats settings | #查看配置设置 | stats settings |
| stats sizes | #展示了固定chunk大小中的items的数量 | Stats sizes |
注意:标识符:一个十六进制无符号的整数(以十进制来表示),需和数据一起存储,get的时候一起返回
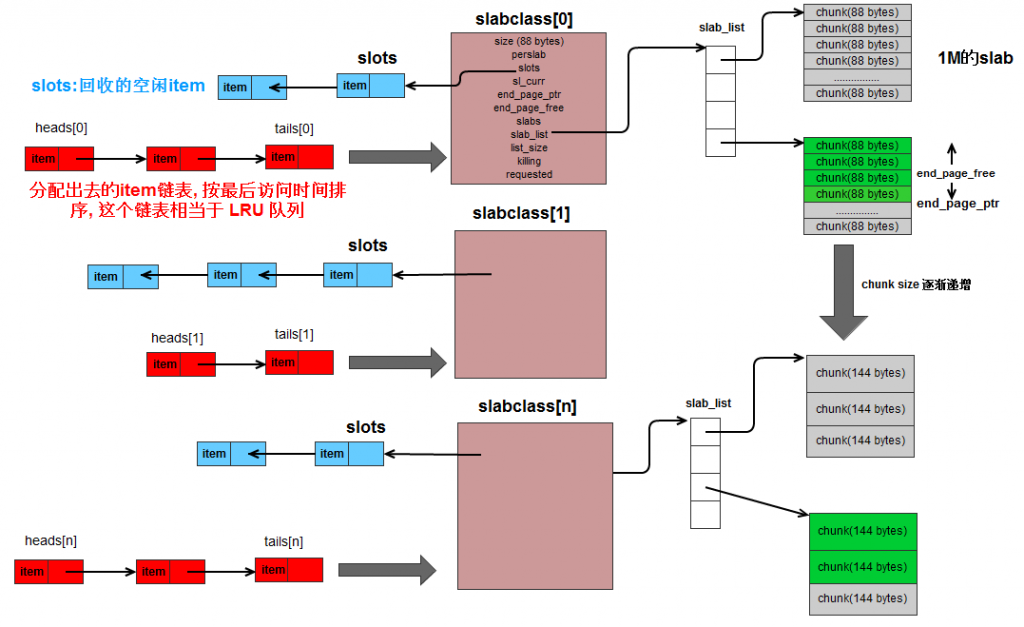
Slab
用于表示存储的最大size数据,仅仅只是用于定义(通俗的讲就是表示可以存储数据大小的范围)。默认情况下,前后两个slab表示存储的size以1.25倍进行增长。例如slab1为96字节,slab2为120字节
Page
分配给Slab的内存空间,默认为1MB。分给Slab后将会根据slab的大小切割成chunk
Chunk
用于缓存记录的内存空间
Slab calss
特定大小的Chunk集合
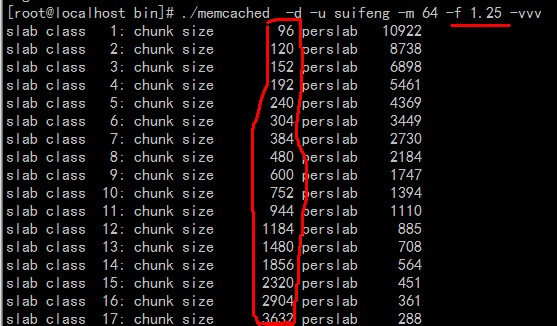
#define ITEM_LINKED 1 //该item插入到LRU队列了
#define ITEM_CAS 2 //该item使用CAS
#define ITEM_SLABBED 4 //该item还在slab的空闲队列里面,没有分配出去
#define ITEM_FETCHED 8 //该item插入到LRU队列后,被worker线程访问过
typedef struct _stritem {
struct _stritem *next;//next指针,用于LRU链表
struct _stritem *prev;//prev指针,用于LRU链表
struct _stritem *h_next;//h_next指针,用于哈希表的冲突链
rel_time_t time;//最后一次访问时间。绝对时间
rel_time_t exptime;//过期失效时间,绝对时间
int nbytes;//本item存放的数据的长度
unsigned short refcount;//本item的引用数
uint8_t nsuffix;//后缀长度 /* length of flags-and-length string */
uint8_t it_flags;//item的属性 /* ITEM_* above */
uint8_t slabs_clsid;/* which slab class we're in */
uint8_t nkey;//键值的长度 /* key length, w/terminating null and padding */
/* this odd type prevents type-punning issues when we do
* the little shuffle to save space when not using CAS. */
union {
uint64_t cas;
char end;
} data[];
/* if it_flags & ITEM_CAS we have 8 bytes CAS */
/* then null-terminated key */
/* then " flags length\r\n" (no terminating null) */
/* then data with terminating \r\n (no terminating null; it's binary!) */
} item;
typedef struct {
unsigned int size; /* sizes of items */
unsigned int perslab; /* how many items per slab */
void *slots; /* list of item ptrs */
unsigned int sl_curr; /* total free items in list */
void *end_page_ptr; /* pointer to next free item at end of page, or 0 */
unsigned int end_page_free; /* number of items remaining at end of last alloced page */
unsigned int slabs; /* how many slabs were allocated for this class */
void **slab_list; /* array of slab pointers */
unsigned int list_size; /* size of prev array */
unsigned int killing; /* index+1 of dying slab, or zero if none */
size_t requested; /* The number of requested bytes */
} slabclass_t;
//将item插入到LRU队列的头部
static void item_link_q(item *it) { /* item is the new head */
item **head, **tail;
assert(it->slabs_clsid < LARGEST_ID); assert((it->it_flags & ITEM_SLABBED) == 0);
head = &heads[it->slabs_clsid];
tail = &tails[it->slabs_clsid];
assert(it != *head);
assert((*head && *tail) || (*head == 0 && *tail == 0));
//头插法插入该item
it->prev = 0;
it->next = *head;
if (it->next) it->next->prev = it;
*head = it;//该item作为对应链表的第一个节点
//如果该item是对应id上的第一个item,那么还会被认为是该id链上的最后一个item
//因为在head那里使用头插法,所以第一个插入的item,到了后面确实成了最后一个item
if (*tail == 0) *tail = it;
sizes[it->slabs_clsid]++;//个数加一
return;
}
static void item_unlink_q(item *it) {
item **head, **tail;
assert(it->slabs_clsid < LARGEST_ID); head = &heads[it->slabs_clsid];
tail = &tails[it->slabs_clsid];
if (*head == it) {//链表上的第一个节点
assert(it->prev == 0);
*head = it->next;
}
if (*tail == it) {//链表上的最后一个节点
assert(it->next == 0);
*tail = it->prev;
}
assert(it->next != it);
assert(it->prev != it);
//把item的前驱节点和后驱节点连接起来
if (it->next) it->next->prev = it->prev;
if (it->prev) it->prev->next = it->next;
sizes[it->slabs_clsid]--;//个数减一
return;
}
#define ITEM_UPDATE_INTERVAL 60 //更新频率为60秒
void do_item_update(item *it) {
//下面的代码可以看到update操作是耗时的。如果这个item频繁被访问,
//那么会导致过多的update,过多的一系列费时操作。此时更新间隔就应运而生
//了。如果上一次的访问时间(也可以说是update时间)距离现在(current_time)
//还在更新间隔内的,就不更新。超出了才更新。
if (it->time < current_time - ITEM_UPDATE_INTERVAL) { mutex_lock(&cache_lock); if ((it->it_flags & ITEM_LINKED) != 0) {
item_unlink_q(it);//从LRU队列中删除
it->time = current_time;//更新访问时间
item_link_q(it);//插入到LRU队列的头部
}
mutex_unlock(&cache_lock);
}
}
static int do_slabs_newslab(const unsigned int id) {
slabclass_t *p = &slabclass[id];
int len = settings.slab_reassign ? settings.item_size_max
: p->size * p->perslab;
char *ptr;
if ((mem_limit && mem_malloced + len > mem_limit && p->slabs > 0) ||
(grow_slab_list(id) == 0) ||
((ptr = memory_allocate((size_t)len)) == 0)) {
MEMCACHED_SLABS_SLABCLASS_ALLOCATE_FAILED(id);
return 0;
}
memset(ptr, 0, (size_t)len);
p->end_page_ptr = ptr;
p->end_page_free = p->perslab;
p->slab_list[p->slabs++] = ptr;
mem_malloced += len;
MEMCACHED_SLABS_SLABCLASS_ALLOCATE(id);
return 1;
}
static void *do_slabs_alloc(const size_t size, unsigned int id) {
slabclass_t *p;
void *ret = NULL;
item *it = NULL;
if (id < POWER_SMALLEST || id > power_largest) {
MEMCACHED_SLABS_ALLOCATE_FAILED(size, 0);
return NULL;
}
p = &slabclass[id];
assert(p->sl_curr == 0 || ((item *)p->slots)->slabs_clsid == 0);
/* 如果不使用 slab 机制, 则直接从操作系统分配 */
#ifdef USE_SYSTEM_MALLOC
if (mem_limit && mem_malloced + size > mem_limit) {
MEMCACHED_SLABS_ALLOCATE_FAILED(size, id);
return 0;
}
mem_malloced += size;
ret = malloc(size);
MEMCACHED_SLABS_ALLOCATE(size, id, 0, ret);
return ret;
#endif
/* fail unless we have space at the end of a recently allocated page,
we have something on our freelist, or we could allocate a new page */
/* 确保最后一个slab 有空闲的chunk */
if (! (p->end_page_ptr != 0 || p->sl_curr != 0 ||
do_slabs_newslab(id) != 0)) {
/* We don't have more memory available */
ret = NULL;
} else if (p->sl_curr != 0) {
/* 从空闲list分配一个item */
/* return off our freelist */
it = (item *)p->slots;
p->slots = it->next;
if (it->next) it->next->prev = 0;
p->sl_curr--;
ret = (void *)it;
} else {
/* 从最后一个slab中分配一个空闲chunk */
/* if we recently allocated a whole page, return from that */
assert(p->end_page_ptr != NULL);
ret = p->end_page_ptr;
if (--p->end_page_free != 0) {
p->end_page_ptr = ((caddr_t)p->end_page_ptr) + p->size;
} else {
p->end_page_ptr = 0;
}
}
if (ret) {
p->requested += size;
MEMCACHED_SLABS_ALLOCATE(size, id, p->size, ret);
} else {
MEMCACHED_SLABS_ALLOCATE_FAILED(size, id);
}
return ret;
}
item *do_item_alloc(char *key, const size_t nkey, const int flags, const rel_time_t exptime, const int nbytes) {
uint8_t nsuffix;
item *it = NULL;
char suffix[40];
size_t ntotal = item_make_header(nkey + 1, flags, nbytes, suffix, &nsuffix);
if (settings.use_cas) {
ntotal += sizeof(uint64_t);
}
unsigned int id = slabs_clsid(ntotal);
if (id == 0)
return 0;
mutex_lock(&cache_lock);
/* do a quick check if we have any expired items in the tail.. */
item *search;
rel_time_t oldest_live = settings.oldest_live;
search = tails[id];
if (search != NULL && (refcount_incr(&search->refcount) == 2)) {
/* 先检查 LRU 队列最后一个 item 是否超时, 超时的话就把这个 item 分配给用户 */
if ((search->exptime != 0 && search->exptime < current_time) || (search->time <= oldest_live && oldest_live <= current_time)) { // dead by flush STATS_LOCK(); stats.reclaimed++; STATS_UNLOCK(); itemstats[id].reclaimed++; if ((search->it_flags & ITEM_FETCHED) == 0) {
STATS_LOCK();
stats.expired_unfetched++;
STATS_UNLOCK();
itemstats[id].expired_unfetched++;
}
it = search;
slabs_adjust_mem_requested(it->slabs_clsid, ITEM_ntotal(it), ntotal);
/* 把这个 item 从 LRU 队列和哈希表中移除 */
do_item_unlink_nolock(it, hash(ITEM_key(it), it->nkey, 0));
/* Initialize the item block: */
it->slabs_clsid = 0;
/* 没有超时的 item, 那就尝试从 slabclass 分配, 运气不好的话, 分配失败,
那就把 LRU 队列最后一个 item 剔除, 然后分配给用户 */
} else if ((it = slabs_alloc(ntotal, id)) == NULL) {
if (settings.evict_to_free == 0) {
itemstats[id].outofmemory++;
pthread_mutex_unlock(&cache_lock);
return NULL;
}
itemstats[id].evicted++;
itemstats[id].evicted_time = current_time - search->time;
if (search->exptime != 0)
itemstats[id].evicted_nonzero++;
if ((search->it_flags & ITEM_FETCHED) == 0) {
STATS_LOCK();
stats.evicted_unfetched++;
STATS_UNLOCK();
itemstats[id].evicted_unfetched++;
}
STATS_LOCK();
stats.evictions++;
STATS_UNLOCK();
it = search;
slabs_adjust_mem_requested(it->slabs_clsid, ITEM_ntotal(it), ntotal);
/* 把这个 item 从 LRU 队列和哈希表中移除 */
do_item_unlink_nolock(it, hash(ITEM_key(it), it->nkey, 0));
/* Initialize the item block: */
it->slabs_clsid = 0;
} else {
refcount_decr(&search->refcount);
}
/* LRU 队列是空的, 或者锁住了, 那就只能从 slabclass 分配内存 */
} else {
/* If the LRU is empty or locked, attempt to allocate memory */
it = slabs_alloc(ntotal, id);
if (search != NULL)
refcount_decr(&search->refcount);
}
if (it == NULL) {
itemstats[id].outofmemory++;
/* Last ditch effort. There was a very rare bug which caused
* refcount leaks. We leave this just in case they ever happen again.
* We can reasonably assume no item can stay locked for more than
* three hours, so if we find one in the tail which is that old,
* free it anyway.
*/
if (search != NULL &&
search->refcount != 2 &&
search->time + TAIL_REPAIR_TIME < current_time) { itemstats[id].tailrepairs++; search->refcount = 1;
do_item_unlink_nolock(search, hash(ITEM_key(search), search->nkey, 0));
}
pthread_mutex_unlock(&cache_lock);
return NULL;
}
assert(it->slabs_clsid == 0);
assert(it != heads[id]);
/* 顺便对 item 做一些初始化 */
/* Item initialization can happen outside of the lock; the item's already
* been removed from the slab LRU.
*/
it->refcount = 1; /* the caller will have a reference */
pthread_mutex_unlock(&cache_lock);
it->next = it->prev = it->h_next = 0;
it->slabs_clsid = id;
DEBUG_REFCNT(it, '*');
it->it_flags = settings.use_cas ? ITEM_CAS : 0;
it->nkey = nkey;
it->nbytes = nbytes;
memcpy(ITEM_key(it), key, nkey);
it->exptime = exptime;
memcpy(ITEM_suffix(it), suffix, (size_t)nsuffix);
it->nsuffix = nsuffix;
return it;
}
int do_item_link(item *it, const uint32_t hv) {
MEMCACHED_ITEM_LINK(ITEM_key(it), it->nkey, it->nbytes);
assert((it->it_flags & (ITEM_LINKED|ITEM_SLABBED)) == 0);
mutex_lock(&cache_lock);
it->it_flags |= ITEM_LINKED;
it->time = current_time;
STATS_LOCK();
stats.curr_bytes += ITEM_ntotal(it);
stats.curr_items += 1;
stats.total_items += 1;
STATS_UNLOCK();
/* Allocate a new CAS ID on link. */
ITEM_set_cas(it, (settings.use_cas) ? get_cas_id() : 0);
/* 把 item 放入哈希表 */
assoc_insert(it, hv);
/* 把 item 放入 LRU 队列*/
item_link_q(it);
refcount_incr(&it->refcount);
pthread_mutex_unlock(&cache_lock);
return 1;
}
void do_item_unlink(item *it, const uint32_t hv) {
MEMCACHED_ITEM_UNLINK(ITEM_key(it), it->nkey, it->nbytes);
mutex_lock(&cache_lock);
if ((it->it_flags & ITEM_LINKED) != 0) {
it->it_flags &= ~ITEM_LINKED;
STATS_LOCK();
stats.curr_bytes -= ITEM_ntotal(it);
stats.curr_items -= 1;
STATS_UNLOCK();
/* 从哈希表中删除 item */
assoc_delete(ITEM_key(it), it->nkey, hv);
/* 从 LRU 队列中删除 item */
item_unlink_q(it);
/* 释放 item 所占的内存 */
do_item_remove(it);
}
pthread_mutex_unlock(&cache_lock);
}
/** wrapper around assoc_find which does the lazy expiration logic */
item *do_item_get(const char *key, const size_t nkey, const uint32_t hv) {
mutex_lock(&cache_lock);
/* 从哈希表中找 item */
item *it = assoc_find(key, nkey, hv);
if (it != NULL) {
refcount_incr(&it->refcount);
/* Optimization for slab reassignment. prevents popular items from
* jamming in busy wait. Can only do this here to satisfy lock order
* of item_lock, cache_lock, slabs_lock. */
if (slab_rebalance_signal &&
((void *)it >= slab_rebal.slab_start && (void *)it < slab_rebal.slab_end)) { do_item_unlink_nolock(it, hv); do_item_remove(it); it = NULL; } } pthread_mutex_unlock(&cache_lock); int was_found = 0; if (settings.verbose > 2) {
if (it == NULL) {
fprintf(stderr, "> NOT FOUND %s", key);
} else {
fprintf(stderr, "> FOUND KEY %s", ITEM_key(it));
was_found++;
}
}
/* 找到了, 然后检查是否超时 */
if (it != NULL) {
if (settings.oldest_live != 0 && settings.oldest_live <= current_time && it->time <= settings.oldest_live) { do_item_unlink(it, hv); do_item_remove(it); it = NULL; if (was_found) { fprintf(stderr, " -nuked by flush"); } } else if (it->exptime != 0 && it->exptime <= current_time) { do_item_unlink(it, hv); do_item_remove(it); it = NULL; if (was_found) { fprintf(stderr, " -nuked by expire"); } } else { it->it_flags |= ITEM_FETCHED;
DEBUG_REFCNT(it, '+');
}
}
if (settings.verbose > 2)
fprintf(stderr, "\n");
return it;
}
unsigned int slabs_clsid(const size_t size) {//返回slabclass索引下标值
int res = POWER_SMALLEST;//res的初始值为1
//返回0表示查找失败,因为slabclass数组中,第一个元素是没有使用的
if (size == 0)
return 0;
//因为slabclass数组中各个元素能分配的item大小是升序的
//所以从小到大直接判断即可在数组找到最小但又能满足的元素
while (size > slabclass[res].size)
if (res++ == power_largest) /* won't fit in the biggest slab */
return 0;
return res;
}
Links:
http://blog.csdn.net/luotuo44/article/details/42963793
using System.Collections.Generic;
using System.Threading;
namespace Lru
{
public class LRUCache<TKey, TValue>
{
const int DEFAULT_CAPACITY = 255;
int _capacity;
ReaderWriterLockSlim _locker;
IDictionary<TKey, TValue> _dictionary;
LinkedList _linkedList;
public LRUCache() : this(DEFAULT_CAPACITY) { }
public LRUCache(int capacity)
{
_locker = new ReaderWriterLockSlim();
_capacity = capacity > 0 ? capacity : DEFAULT_CAPACITY;
_dictionary = new Dictionary<TKey, TValue>();
_linkedList = new LinkedList();
}
public void Set(TKey key, TValue value)
{
_locker.EnterWriteLock();
try
{
_dictionary[key] = value;
_linkedList.Remove(key);
_linkedList.AddFirst(key);
if (_linkedList.Count > _capacity)
{
_dictionary.Remove(_linkedList.Last.Value);
_linkedList.RemoveLast();
}
}
finally { _locker.ExitWriteLock(); }
}
public bool TryGet(TKey key, out TValue value)
{
_locker.EnterUpgradeableReadLock();
try
{
bool b = _dictionary.TryGetValue(key, out value);
if (b)
{
_locker.EnterWriteLock();
try
{
_linkedList.Remove(key);
_linkedList.AddFirst(key);
}
finally { _locker.ExitWriteLock(); }
}
return b;
}
catch { throw; }
finally { _locker.ExitUpgradeableReadLock(); }
}
public bool ContainsKey(TKey key)
{
_locker.EnterReadLock();
try
{
return _dictionary.ContainsKey(key);
}
finally { _locker.ExitReadLock(); }
}
public int Count
{
get
{
_locker.EnterReadLock();
try
{
return _dictionary.Count;
}
finally { _locker.ExitReadLock(); }
}
}
public int Capacity
{
get
{
_locker.EnterReadLock();
try
{
return _capacity;
}
finally { _locker.ExitReadLock(); }
}
set
{
_locker.EnterUpgradeableReadLock();
try
{
if (value > 0 && _capacity != value)
{
_locker.EnterWriteLock();
try
{
_capacity = value;
while (_linkedList.Count > _capacity)
{
_linkedList.RemoveLast();
}
}
finally { _locker.ExitWriteLock(); }
}
}
finally { _locker.ExitUpgradeableReadLock(); }
}
}
public ICollection Keys
{
get
{
_locker.EnterReadLock();
try
{
return _dictionary.Keys;
}
finally { _locker.ExitReadLock(); }
}
}
public ICollection Values
{
get
{
_locker.EnterReadLock();
try
{
return _dictionary.Values;
}
finally { _locker.ExitReadLock(); }
}
}
}
}
来源:http://www.itwendao.com/article/detail/243752.html
1.创建全文索引(FullText index)
旧版的MySQL的全文索引只能用在MyISAM表格的char、varchar和text的字段上。
不过新版的MySQL5.6.24上InnoDB引擎也加入了全文索引,所以具体信息要随时关注官网,
1.1. 创建表的同时创建全文索引
CREATE TABLE article (
id INT AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT(title, body)
) TYPE=MYISAM;
1.2.通过 alter table 的方式来添加
ALTER TABLE `student` ADD FULLTEXT INDEX ft_stu_name (`name`) #ft_stu_name是索引名,可以随便起
或者:ALTER TABLE `student` ADD FULLTEXT ft_stu_name (`name`)
1.3. 直接通过create index的方式
CREATE FULLTEXT INDEX ft_email_name ON `student` (`name`)
也可以在创建索引的时候指定索引的长度:
CREATE FULLTEXT INDEX ft_email_name ON `student` (`name`(20))
2. 删除全文索引
2.1. 直接使用 drop index(注意:没有 drop fulltext index 这种用法)
DROP INDEX full_idx_name ON tommy.girl ;
2.2. 使用 alter table的方式
ALTER TABLE tommy.girl DROP INDEX ft_email_abcd;
3.使用全文索引
跟普通索引稍有不同
使用全文索引的格式: MATCH (columnName) AGAINST ('string')
eg:
SELECT * FROM `student` WHERE MATCH(`name`) AGAINST('聪')
当查询多列数据时:
建议在此多列数据上创建一个联合的全文索引,否则使用不了索引的。
SELECT * FROM `student` WHERE MATCH(`name`,`address`) AGAINST('聪 广东')
3.1. 使用全文索引需要注意的是:(基本单位是词)
分词,全文索引以词为基础的,MySQL默认的分词是所有非字母和数字的特殊符号都是分词符(外国人嘛)
这里推荐一篇文章:利用mysql的全文索引实现模糊查询
3.2. MySQL中与全文索引相关的几个变量:
使用命令:mysql> SHOW VARIABLES LIKE 'ft%'; #ft就是FullText的简写
ft_boolean_syntax + -><()~*:""&| #改变IN BOOLEAN MODE的查询字符,不用重新启动MySQL也不用重建索引 ft_min_word_len 4 #最短的索引字符串,默认值为4,(通常改为1)修改后必须重建索引文件 重新建立索引命令:repair table tablename quick ft_max_word_len 84 #最长的索引字符串,默认值为84,修改后必须重建索引文件 ft_query_expansion_limit 20 #查询括展时取最相关的几个值用作二次查询 ft_stopword_file (built-in) #全文索引的过滤词文件,具体可以参考:MySQL全文检索中不进行全文索引默认过滤词 特别注意:50%的门坎限制(当查询结果很多,几乎所有记录都有,或者极少的数据,都有可能会返回非所期望的结果) -->可用IN BOOLEAN MODE即可以避开50%的限制。
此时使用全文索引的格式就变成了: SELECT * FROM `student` WHERE MATCH(`name`) AGAINST('聪' IN BOOLEAN MODE)
更多内容请参考:MySQL中的全文检索(1)
4. ft_boolean_syntax (+ -><()~*:""&|)使用的例子: 4.1 + : 用在词的前面,表示一定要包含该词,并且必须在开始位置。 eg: +Apple 匹配:Apple123, "tommy, Apple" 4.2 - : 不包含该词,所以不能只用「-yoursql」这样是查不到任何row的,必须搭配其他语法使用。 eg: MATCH (girl_name) AGAINST ('-林志玲 +张筱雨') 匹配到: 所有不包含林志玲,但包含张筱雨的记录 4.3. 空(也就是默认情况),表示可选的,包含该词的顺序较高。 例子: apple banana 找至少包含上面词中的一个的记录行 +apple +juice 两个词均在被包含 +apple macintosh 包含词 “apple”,但是如果同时包含 “macintosh”,它的排列将更高一些 +apple -macintosh 包含 “apple” 但不包含 “macintosh” 4.4. > :提高该字的相关性,查询的结果会排在比较靠前的位置。
4.5.< :降低相关性,查询的结果会排在比较靠后的位置。 例子:4.5.1.先不使用 >< select * from tommy.girl where match(girl_name) against('张欣婷' in boolean mode); 可以看到完全匹配的排的比较靠前 4.5.2. 单独使用 >
select * from tommy.girl where match(girl_name) against('张欣婷 >李秀琴' in boolean mode);
使用了>的李秀琴马上就排到最前面了
4.5.3. 单独使用 <
select * from tommy.girl where match(girl_name) against('张欣婷 <不是人' in boolean mode);
看到没,不是人也排到最前面了,这里使用的可是 < 哦,说好的降低相关性呢,往下看吧。 4.5.4.同时使用>< select * from tommy.girl where match(girl_name) against('张欣婷 >李秀琴 <练习册 <不是人>是个鬼' in boolean mode);
到这里终于有答案了,只要使用了 ><的都会往前排,而且>的总是排在<的前面 小结一下:1. 只要使用 ><的总比没用的 靠前; 2. 使用 >的一定比 <的排的靠前 (这就符合相关性提高和降低); 3. 使用同一类的,使用的越早,排的越前。 4.6. ( ):可以通过括号来使用字条件。 eg: +aaa +(>bbb <ccc) // 找到有aaa和bbb和ccc,aaa和bbb,或者aaa和ccc(因为bbb,ccc前面没有+,所以表示可有可无), 然后 aaa&bbb > aaa&bbb&ccc > aaa&ccc
4.7. ~ :将其相关性由正转负,表示拥有该字会降低相关性,但不像「-」将之排除,只是排在较后面。
eg: +apple ~macintosh 先匹配apple,但如果同时包含macintosh,就排名会靠后。
4.8. * :通配符,这个只能接在字符串后面。
MATCH (girl_name) AGAINST ('+*ABC*') #错误,不能放前面
MATCH (girl_name) AGAINST ('+张筱雨*') #正确
4.9. " " :整体匹配,用双引号将一段句子包起来表示要完全相符,不可拆字。
eg: "tommy huang" 可以匹配 tommy huang xxxxx 但是不能匹配 tommy is huang。
5.补充:Windows下无法修改 ft_min_word_len的情况,
5. 1. 使用cmd打开 services.msc,
找到你的 MySQL服务,右键Properties,找到你的my.ini所在的路径
5.2. 停止MySQL,在my.ini中增加 ft_min_word_len = 1,重启MySQL,
然后使用命令 show variables like 'ft_min_word_len'; 查看是否生效了