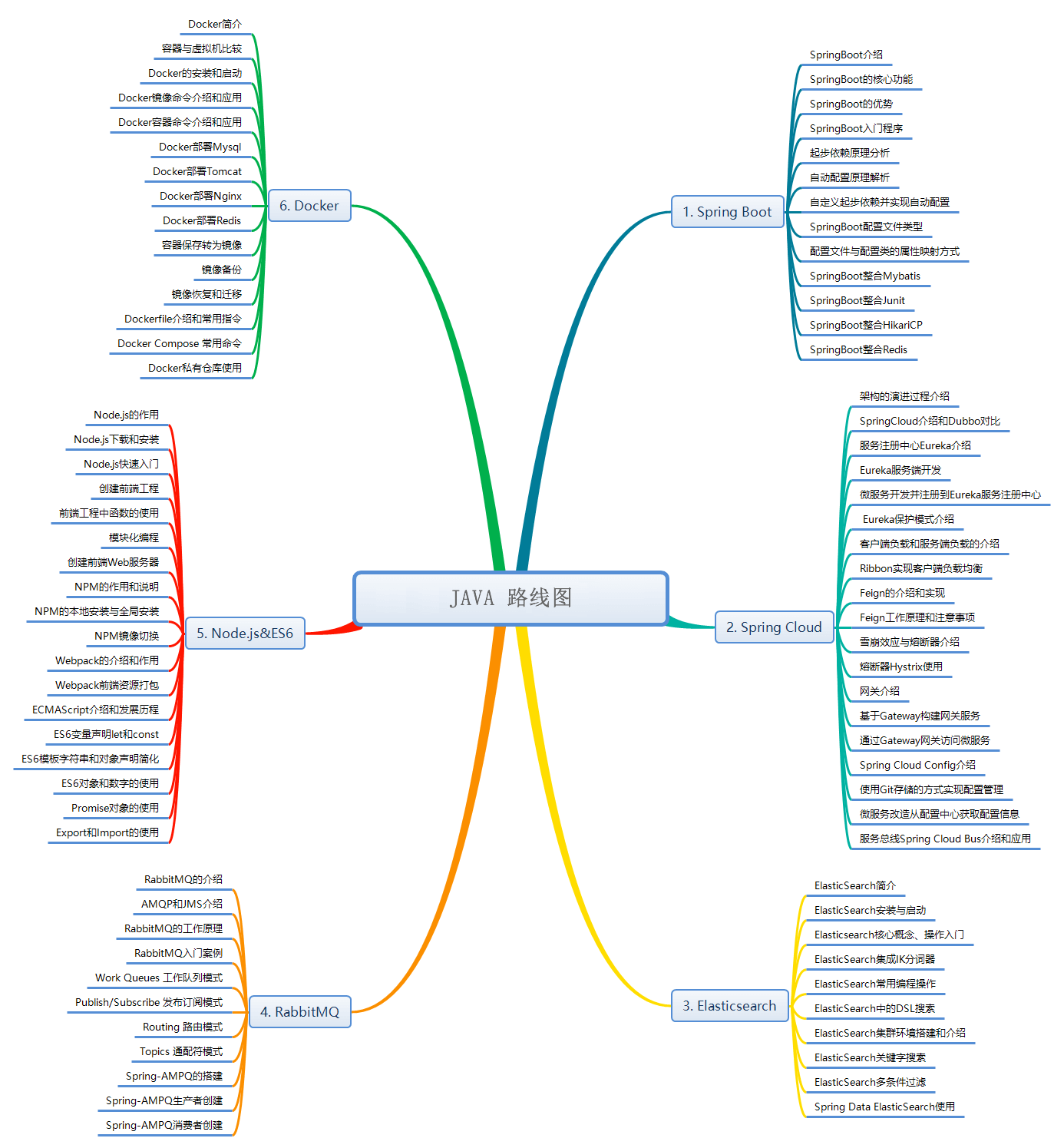
服务
pom.xml
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.9.2</version>
</dependency>Swagger2.java:
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import springfox.documentation.builders.ApiInfoBuilder;
import springfox.documentation.builders.ParameterBuilder;
import springfox.documentation.builders.PathSelectors;
import springfox.documentation.builders.RequestHandlerSelectors;
import springfox.documentation.schema.ModelRef;
import springfox.documentation.service.*;
import springfox.documentation.spi.DocumentationType;
import springfox.documentation.spi.service.contexts.SecurityContext;
import springfox.documentation.spring.web.plugins.Docket;
import springfox.documentation.swagger2.annotations.EnableSwagger2;
import java.util.ArrayList;
import java.util.List;
@Configuration
@EnableSwagger2
public class Swagger2 {
/**
* 创建API应用
* apiInfo() 增加API相关信息
* 通过select()函数返回一个ApiSelectorBuilder实例,用来控制哪些接口暴露给Swagger来展现,
* 本例采用指定扫描的包路径来定义指定要建立API的目录。
*
* @return
*/
@Bean
public Docket createRestApi() {
ParameterBuilder ticketPar = new ParameterBuilder();
List<Parameter> pars = new ArrayList<Parameter>();
ticketPar.name("X-AUTH").description("token")
.modelRef(new ModelRef("string"))
.parameterType("header")
.required(false)
.build();
pars.add(ticketPar.build());
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.select()
.apis(RequestHandlerSelectors.basePackage("cn.user.controller"))
.paths(PathSelectors.any())
.build()
.securitySchemes(securitySchemes())
.securityContexts(securityContexts());
}
private List<ApiKey> securitySchemes() {
List<ApiKey> apiKeyList= new ArrayList();
apiKeyList.add(new ApiKey("X-AUTH", "X-AUTH", "header"));
return apiKeyList;
}
private List<SecurityContext> securityContexts() {
List<SecurityContext> securityContexts=new ArrayList<>();
securityContexts.add(
SecurityContext.builder()
.securityReferences(defaultAuth())
.forPaths(PathSelectors.regex("^(?!auth).*$"))
.build());
return securityContexts;
}
List<SecurityReference> defaultAuth() {
AuthorizationScope authorizationScope = new AuthorizationScope("global", "accessEverything");
AuthorizationScope[] authorizationScopes = new AuthorizationScope[1];
authorizationScopes[0] = authorizationScope;
List<SecurityReference> securityReferences=new ArrayList<>();
securityReferences.add(new SecurityReference("X-AUTH", authorizationScopes));
return securityReferences;
}
/**
* 创建该API的基本信息(这些基本信息会展现在文档页面中)
* 访问地址:/swagger-ui.html
* @return
*/
private ApiInfo apiInfo() {
return new ApiInfoBuilder().title("用户相关接口").build();
}
}
网关(Gateway)
pom.xml
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-common</artifactId>
<version>2.8.0</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.8.0</version>
</dependency>
SwaggerHandler
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Mono;
import springfox.documentation.swagger.web.*;
import java.util.Optional;
@RestController
public class SwaggerHandler {
@Autowired(required = false)
private SecurityConfiguration securityConfiguration;
@Autowired(required = false)
private UiConfiguration uiConfiguration;
private final SwaggerResourcesProvider swaggerResources;
@Autowired
public SwaggerHandler(SwaggerResourcesProvider swaggerResources) {
this.swaggerResources = swaggerResources;
}
@GetMapping("/swagger-resources/configuration/security")
public Mono<ResponseEntity<SecurityConfiguration>> securityConfiguration() {
return Mono.just(new ResponseEntity<>(
Optional.ofNullable(securityConfiguration).orElse(SecurityConfigurationBuilder.builder().build()), HttpStatus.OK));
}
@GetMapping("/swagger-resources/configuration/ui")
public Mono<ResponseEntity<UiConfiguration>> uiConfiguration() {
return Mono.just(new ResponseEntity<>(
Optional.ofNullable(uiConfiguration).orElse(UiConfigurationBuilder.builder().build()), HttpStatus.OK));
}
@GetMapping("/swagger-resources")
public Mono<ResponseEntity> swaggerResources() {
return Mono.just((new ResponseEntity<>(swaggerResources.get(), HttpStatus.OK)));
}
@GetMapping("/")
public Mono<ResponseEntity> swaggerResourcesN() {
return Mono.just((new ResponseEntity<>(swaggerResources.get(), HttpStatus.OK)));
}
@GetMapping("/csrf")
public Mono<ResponseEntity> swaggerResourcesCsrf() {
return Mono.just((new ResponseEntity<>(swaggerResources.get(), HttpStatus.OK)));
}
}
SwaggerProvider
import lombok.AllArgsConstructor;
import org.springframework.cloud.gateway.config.GatewayProperties;
import org.springframework.cloud.gateway.route.RouteLocator;
import org.springframework.cloud.gateway.support.NameUtils;
import org.springframework.context.annotation.Primary;
import org.springframework.stereotype.Component;
import springfox.documentation.swagger.web.SwaggerResource;
import springfox.documentation.swagger.web.SwaggerResourcesProvider;
import java.util.ArrayList;
import java.util.List;
@Component
@Primary
@AllArgsConstructor
public class SwaggerProvider implements SwaggerResourcesProvider {
public static final String API_URI = "/v2/api-docs";
private final RouteLocator routeLocator;
private final GatewayProperties gatewayProperties;
@Override
public List<SwaggerResource> get() {
List<SwaggerResource> resources = new ArrayList<>();
List<String> routes = new ArrayList<>();
//取出gateway的route
routeLocator.getRoutes().subscribe(route -> routes.add(route.getId()));
//结合配置的route-路径(Path),和route过滤,只获取有效的route节点
gatewayProperties.getRoutes().stream().filter(routeDefinition -> routes.contains(routeDefinition.getId()))
.forEach(routeDefinition -> routeDefinition.getPredicates().stream()
.filter(predicateDefinition -> ("Path").equalsIgnoreCase(predicateDefinition.getName()))
.forEach(predicateDefinition -> resources.add(swaggerResource(routeDefinition.getId(),
predicateDefinition.getArgs().get(NameUtils.GENERATED_NAME_PREFIX + "0")
.replace("/**", API_URI)))));
return resources;
}
private SwaggerResource swaggerResource(String name, String location) {
SwaggerResource swaggerResource = new SwaggerResource();
swaggerResource.setName(name);
swaggerResource.setLocation(location);
swaggerResource.setSwaggerVersion("2.0");
return swaggerResource;
}
}
.